WHAT IS VECTOR MEMORY ARCHITECTURE FOR AI AGENTS?
⚡ TL;DR — Quick Summary
KEY TAKEAWAYS
QUICK ANSWER — For AI Overviews & Decision-Stage Buyers
Vector Memory Architecture for AI Agents
EXECUTIVE SUMMARY: THE MEMORY DESIGN PROBLEM
Most production AI agents in 2026 have no memory architecture. They have a RAG pipeline. A RAG pipeline retrieves context at query time from a flat vector collection and discards it after the response is generated. The agent has no continuity between sessions, no validated ground truth separated from provisional reasoning, no decision history to self-correct against, and no function schema registry to prevent API hallucination. Every session starts from zero. Every retrieval competes with every other retrieval in the same undifferentiated collection. The longer the agent runs, the more degraded its retrieval precision becomes as unmanaged vectors accumulate.
This is not a model limitation. It is a memory design failure.
Moving from Flat RAG Retrieval one collection, one embedding space, one retrieval pattern to Layered Sovereign Memory. Each memory type has a purpose, a storage backend, a retrieval latency requirement, a TTL or lifecycle rule, and a failure mode that is addressable by architecture before the first query fires.
An agent that maintains context fidelity across sessions. A long-term memory store where ground truth never mixes with provisional reasoning. An episodic log that enables multi-session continuity and self-correction. A tool memory registry that eliminates API hallucination. A memory system that degrades gracefully under load rather than silently producing wrong outputs with high confidence.
2026 Memory Architecture Law: In a production AI agent deployment, memory architecture determines output quality ceiling. The model determines what the agent can reason about. The memory architecture determines whether that reasoning is grounded in correct, current, and relevant context or in stale, contaminated, and geometrically misaligned noise.
WHY THIS POST EXISTS AND WHAT IT DOES NOT COVER
The best vector database for AI agents pillar at ranksquire.com/2026/01/07/best-vector-database-ai-agents/ covers database selection: which of the six databases to use and why, based on use case, compliance requirements, and TCO. That is the decision framework. This post is the memory system design layer what goes inside the databases you have already selected.
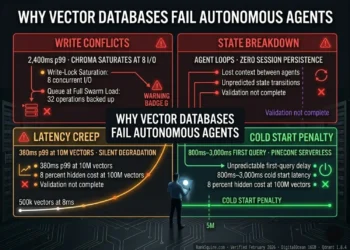
Why Vector Databases Fail Autonomous Agents at ranksquire.com/2026/03/09/why-vector-databases-fail-autonomous-agents-2/ covers what breaks at the infrastructure level: write conflicts, state management breakdown, latency creep, cold start penalties. This post is the layer above that — what the agent is actually storing in those databases and why the layering matters for output quality.
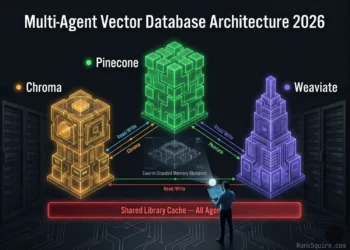
Multi-Agent Vector Database Architecture at ranksquire.com/2026/multi-agent-vector-database-architecture-2026/ covers swarm-level memory isolation for multi-agent systems: namespace partitioning, Context Collision prevention, the Swarm-Sharded Memory Blueprint. This post is its foundation layer the single-agent memory architecture that swarm namespace design is built on top of.
A vector memory architecture for agentic AI has three system layers: the Encoding Layer converts experience into vectors, the Storage Layer persists them in latency-matched backends, and the Retrieval Layer selects and assembles them into reasoning context. A database without this three-layer architecture is not a memory system. It is unsorted storage with a search API. Verified March 2026.
Table of Contents
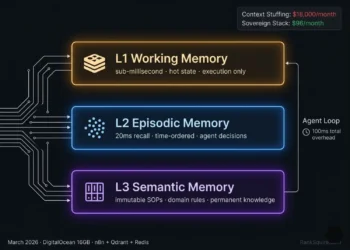
1. THE FOUR MEMORY LAYER TYPES

Not all agent memory is the same. Treating all agent context as a single retrieval problem one collection, one embedding space, one query pattern is the foundational error that produces the three failure modes this post addresses. The four memory types have categorically different retrieval requirements, storage characteristics, and failure modes.
MEMORY TYPE 1: SHORT-TERM MEMORY (Working State)
Definition: The agent’s current task state. Active session variables, in-progress tool call outputs, current task parameters, loop counters, intermediate calculation results.
Retrieval requirement: Sub-millisecond. The agent accesses working state continuously during task execution every decision branch checks current state before proceeding.
Storage backend: Redis OSS, session-scoped key-value with TTL. Not a vector database. Short-term memory is structured state, not semantic content. Embedding it and querying it by similarity adds 20ms of unnecessary latency to every working state access.
Lifecycle: Expires at TTL matching session duration. Never persists to long-term memory without an explicit validation gate. A session’s provisional intermediate state is not domain knowledge.
Critical failure mode: Absent TTL. Short-term memory without expiry becomes long-term memory by accumulation. An agent processing 200 sessions per day without TTL on working state accumulates 200 × session_variable_count stale records per day in the retrieval pool. By day 30 the collection contains 6,000 stale working state records competing with ground truth in every similarity query. The agent begins retrieving its own old intermediate states as current context.
MEMORY TYPE 2: LONG-TERM MEMORY (Domain Knowledge)
Definition: Persistent validated domain knowledge. SOPs, compliance rules, product specifications, validated factual records, approved reasoning frameworks.
Retrieval requirement: 20ms p99. Long-term memory retrieval fires on every user query and major task step it must be fast but does not require the sub-millisecond speed of working state access.
Storage backend: Qdrant with HNSW indexing, Binary Quantization, pre-scan payload filtering by document_type and validation_status.
Lifecycle: Updated by Admin process only. Never written to by the agent during task execution. An agent that can write to its own long-term memory store during execution is an agent that will eventually contaminate its ground truth with its own unvalidated intermediate reasoning.
Critical failure mode: No validation gate on writes. If the agent can write to long-term memory without a Reviewer or Admin validation step, the long-term store accumulates unvalidated agent outputs. Over time, the agent retrieves its own prior provisional conclusions as confirmed domain knowledge. This is the Hallucination Amplification failure mode covered in Section 8.
MEMORY TYPE 3: EPISODIC MEMORY (Decision History)
Definition: Time-ordered record of agent decisions, tool call sequences, external API responses, and outcome assessments across sessions.
Retrieval requirement: Sequential time-series. The agent reconstructs its decision history not by semantic similarity (what is most similar to my current query) but by temporal sequence (what did I do in this task domain, in what order, with what outcomes).
Storage backend: Pinecone Serverless for elastic scale under variable session load, or Qdrant with Unix timestamp payload and strict time-range filtering for sovereign deployments.
Lifecycle: Append-only during agent execution. Agent writes to episodic memory but never deletes from it during execution. Cleanup is an Admin process only, with configurable retention window (e.g., 90 days for compliance, 30 days for general deployment).
Critical failure mode: Using semantic similarity retrieval instead of time-ordered sequential retrieval for episodic context. If the agent retrieves “most similar past decisions” instead of “most recent past decisions in this task domain,” it may retrieve episodically distant but semantically close records reconstructing a decision chain that is factually accurate in isolation but temporally incorrect for the current session context.
MEMORY TYPE 4: TOOL MEMORY (Function Schema Registry)
Definition: The agent’s registry of available tools, functions, APIs, and capabilities. Function signatures, parameter specifications, authentication requirements, rate limits, error response formats.
Retrieval requirement: Hybrid BM25 + dense vector. Tool memory retrieval combines exact string matching (specific function names, parameter names, endpoint paths) with semantic similarity (what tool handles this type of task). Pure semantic search returns tools that are conceptually related but functionally different. Pure keyword search misses tool aliases and semantic variants.
Storage backend: Weaviate for native hybrid BM25 + dense search in a single query at 44ms p99 at 10M vectors. Qdrant with BM25 post-processing for sovereign deployments where Weaviate cloud adds unacceptable latency.
Lifecycle: Versioned. Every tool schema update creates a new version record. The agent always queries the current version by default. Rollback is available via version_id metadata filter.
Critical failure mode: Unversioned tool memory. A function schema update that changes parameter names without a version increment produces agents that call functions with outdated signatures. The API returns a 400 error. The agent has no visibility into why. It has the correct function name and retrieved what it believed was the current specification. This failure is architectural, not agent-level. Versioning is the fix.
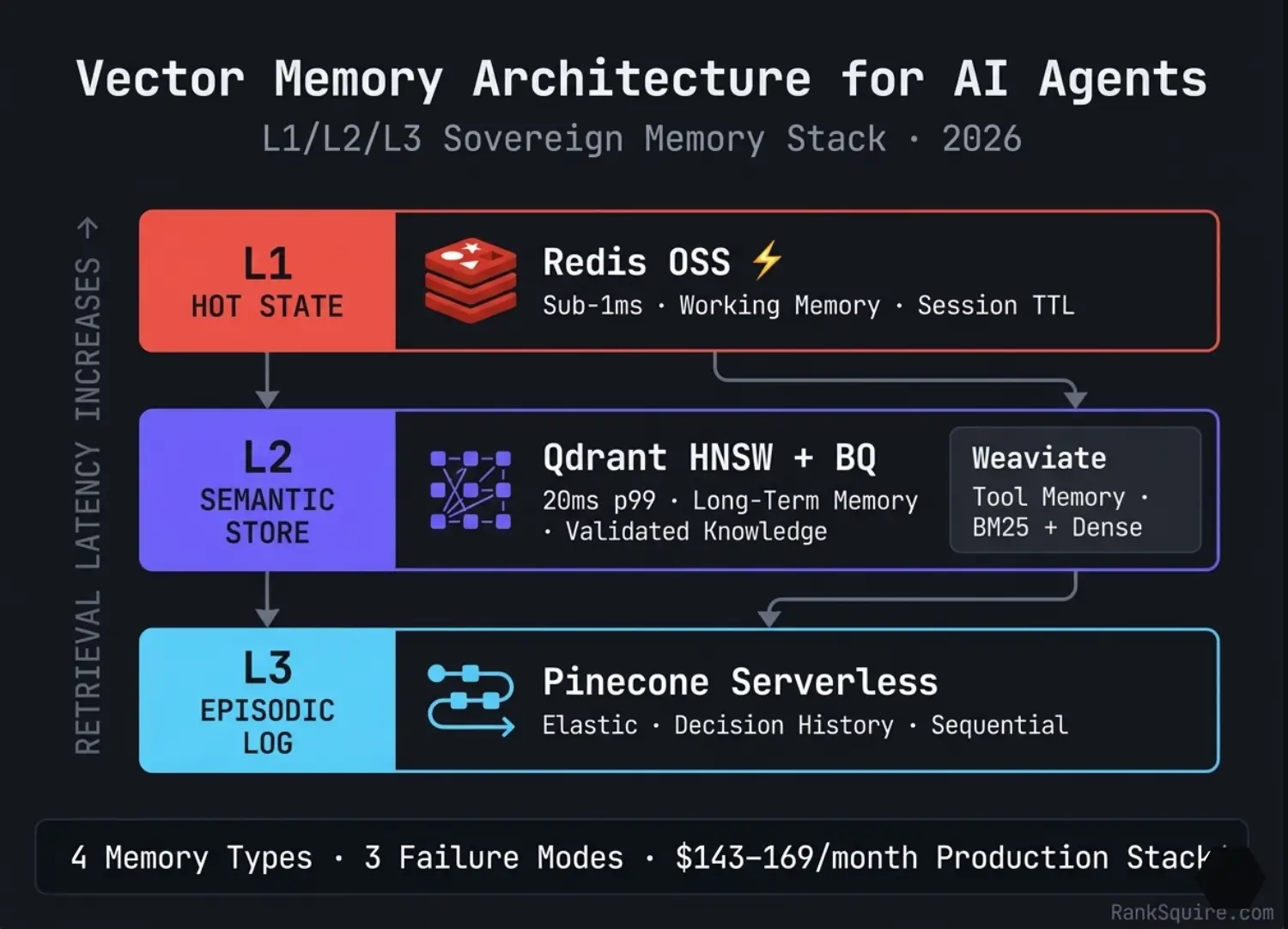
2. THE L1/L2/L3 SOVEREIGN MEMORY STACK STORAGE MAPPING
L1/L2/L3 NAMING CONVENTION
TABLE: L1/L2/L3 Sovereign Memory Stack — Configuration Reference — March 2026
| LAYER | MEMORY TYPE | BACKEND | LATENCY | WRITE PATTERN | LIFECYCLE |
|---|---|---|---|---|---|
| L1 | Short-term working state | Redis OSS co-located | sub-1ms | Agent writes ‧ session-scoped TTL | Expires at session end |
| L1 | Tool memory hot cache | Redis (cache layer before Weaviate) | sub-1ms | Cache miss refreshes from L2 | TTL = tool schema update cadence |
| L2 | Long-term domain knowledge | Qdrant HNSW + BQ | 20ms p99 | Admin writes only | Persistent, versioned |
| L2 | Tool schema registry | Weaviate hybrid / Qdrant | 26–44ms | Versioned Admin writes | Versioned, rollback available |
| L3 | Episodic decision log | Pinecone Serverless / Qdrant | Elastic | Agent writes, append-only | Retention window (30–90 days) |
3. SHORT-TERM MEMORY: DESIGN, TTL, AND OVERFLOW PREVENTION
Short-term memory is the layer engineers most frequently under-engineer. The failure mode is not dramatic it is gradual and invisible. Retrieval precision degrades over days as stale session state accumulates. The agent does not error. It retrieves its own old working context, treats it as current domain knowledge, and produces confident output from stale intermediate state.
TTL DESIGN — SESSION-SCOPED
st_{agent_id}{session_id}{variable_name}
This naming prevents collision across concurrent sessions on the same agent. An agent running 10 concurrent sessions with a single flat key space produces cross-session state contamination — agents reading each other’s in-progress variable values via shared key names.
OVERFLOW PREVENTION — ACTIVE PRUNING
Beyond TTL-based expiry, production agents require active pruning of short-term memory during long-running sessions. An agent executing a 3-hour autonomous task may accumulate 10,000+ working state entries within a single TTL window. Without active pruning, working state grows unbounded within the session.
Retain only the N most recent entries per variable category. N is domain-specific. For a reasoning agent tracking intermediate conclusions: N = 20. For a data processing agent tracking row-level results: N = 100.
Add a Pruning Workflow triggered on a 15-minute cron schedule during active sessions. Query Redis key count by agent_id prefix. If count exceeds threshold, delete oldest entries by timestamp. Zero agent logic changes required — pruning is infrastructure-level.
4. LONG-TERM MEMORY: INDEXING, VALIDATION GATES, AND RETRIEVAL PRECISION
Long-term memory is the agent’s ground truth store. The architectural requirement is simple and non-negotiable: the agent reads from long-term memory. The agent never writes to long-term memory during task execution.
THE VALIDATION GATE
The candidate must originate from an approved source (Admin input, external API with known reliability, Reviewer-approved agent output). Unreviewed agent outputs never enter long-term memory directly.
Before indexing, query the long-term store for cosine similarity above 0.92 threshold. If a near-duplicate exists, update the existing record rather than creating a new vector. Duplicate accumulation degrades retrieval precision by fragmenting a single concept across multiple overlapping records.
Every long-term memory record must carry: document_type, source_id, validation_status (approved or pending), created_at Unix timestamp, version (for updateable records). Without metadata, retrieval cannot be filtered by document type or validation status — the agent retrieves indiscriminately from the full collection.
RETRIEVAL PRECISION — PAYLOAD FILTER FIRST
The single most impactful retrieval precision improvement in long-term memory is pre-scan payload filtering. Query the collection with document_type filter before HNSW traversal — not after.
5. EPISODIC MEMORY: SESSION CONTINUITY AND SELF-CORRECTION
Episodic memory is the layer that transforms a stateless query-response machine into an agent that learns from its own execution history. Without episodic memory, every session starts from zero. The agent cannot recognize that it attempted this task domain three days ago, succeeded with a specific tool sequence, and failed when it deviated from that sequence. It has no basis for self-correction across sessions.
SESSION CONTINUITY PATTERN
On every new session initiation, the agent queries its episodic store for the three most recent sessions in the same task domain. It extracts: what goal was pursued, what tool sequence was used, what the outcome was, and whether the outcome was marked successful by the Reviewer.
This episodic retrieval does not replace the current session’s Long-Term Memory query it augments it. The agent has both validated ground truth (Long-Term Memory, always current) and its own historical execution patterns (Episodic Memory, time-ordered) available at session start.
SELF-CORRECTION PATTERN
When a tool call fails or a validation step flags an error, the agent queries episodic memory with the failure context as the query vector. The retrieval target: similar past failure events and the recovery sequences that resolved them.
Implementation constraint: The recovery sequence stored in episodic memory must include outcome metadata did the recovery work? An agent that retrieves a past recovery attempt that itself failed will compound errors rather than resolve them. Every episodic record must carry outcome_status: success, partial, or failed. Self-correction retrieval must filter for outcome_status = success.
- Agent writes to
staging_{agent_id}Qdrant collection — not to long-term - Record tagged:
validation_status = pending,source = agent,created_at = unix_timestamp - Reviewer n8n workflow fires on new staging entry — approves or rejects within configurable SLA
- Approved records promoted to long-term collection with
validation_status = approved - Rejected records deleted from staging — never reach the retrieval pool
- Trigger: episodic record with
outcome_status = successretrieved and applied successfully in 3+ subsequent sessions - Reviewer flags record for promotion in n8n workflow
- Admin generates generalized semantic summary — strips all session-specific identifiers
- Summary passes validation gate: source check + cosine deduplication above 0.92 + full metadata tagging
- Promoted to long-term Qdrant collection:
document_type = consolidated_pattern - Original episodic record retained:
promotion_status = promotedfor audit trail
- L1 Short-term: TTL = session_max_duration × 1.5 — hard expire, no exceptions
- L2 Long-term domain knowledge: No automatic TTL — manual versioning only. Domain changes create a new version record; old version tagged
deprecated = true - L2 Consolidated patterns: Reviewed quarterly — patterns not retrieved in 90 days flagged for Reviewer assessment
- L3 Episodic log: Retention window 30–90 days, Admin-configurable — older records auto-archived or deleted per policy
- Tool memory: Versioned, never auto-decayed — deprecated versions retained for rollback audits
last_verified timestamp on all long-term records. Flag records where now() - last_verified exceeds the domain’s expected update cadence. Automated TTL expiry is not appropriate for domain knowledge — Reviewer verification is required.Memory Deletion and GDPR Compliance
Any vector memory store that persists information about identifiable users is subject to GDPR Article 17 — the right to erasure. An AI agent processing user interactions, customer data, or personal information must be capable of complete user-scoped memory deletion on request. This is a legal requirement in the EU and increasingly enforced in enterprise AI contracts globally.
Architecture requirements for compliant deletion:
- All vectors must carry
user_idas a payload field — without this, user-scoped deletion is architecturally impossible - Deletion must cover all layers: L1 Redis (prefix scan + delete), L2 Qdrant (payload filter delete), L3 Pinecone (metadata filter delete), Weaviate tool memory if user-specific schemas exist
- After vector deletion, trigger a Qdrant collection optimize operation to rebuild the HNSW graph — a deleted vector leaves an orphaned node that degrades retrieval precision if not resolved
- Maintain a deletion audit log: timestamp, user_id, collections affected, record count deleted
- Deletion must complete within 30 days of request per GDPR Article 12.3
Qdrant deletion by user_id (n8n HTTP Request body):
Redis deletion by user_id prefix:
POST /collections/{name}/index in Qdrant to rebuild the graph and restore retrieval precision. Skipping post-deletion re-indexing degrades recall quality proportionally to the percentage of records deleted. Verified March 2026.MEMORY CONSOLIDATION EPISODIC TO SEMANTIC PROMOTION
Memory consolidation is the process by which high-value episodic records are promoted to long-term semantic memory after validation. Not every agent decision warrants permanent storage but patterns that repeat across sessions, recovery sequences that succeed reliably, and domain insights that generalize beyond a single task are candidates for semantic promotion.
Consolidation trigger: An episodic record with outcome_status = success that has been retrieved and applied successfully in three or more subsequent sessions is a consolidation candidate.
Consolidation procedure:
- Reviewer workflow flags the record for promotion
- Admin generates a generalized semantic summary (stripping session-specific identifiers)
- Summary passes the standard validation gate (source validation + duplication check + metadata tagging)
- Promoted to long-term Qdrant collection with document_type = consolidated_pattern
- Original episodic record retained with promotion_status = promoted for audit trail
Why this matters: Without consolidation, agents re-derive successful patterns from episodic retrieval on every session adding latency and retrieval noise. With consolidation, the pattern lives in L2 as validated ground truth, retrievable at 20ms p99 with no sequential log traversal required. The episodic log taught the agent. The semantic store remembers the lesson.
EPISODIC MEMORY DESIGN RECORD STRUCTURE
6. TOOL MEMORY: FUNCTION SCHEMA REGISTRY AND API HALLUCINATION PREVENTION
Tool memory is the most consequential and most under-architected memory layer in production agents as of March 2026. The failure mode is acute: an agent calls a function with the correct intent but the wrong parameter signature, the API returns a 400 error, and the agent has no basis for understanding why because it retrieved what it believed was the current specification.
Tool memory failures do not look like hallucinations. They look like API errors. The root cause is memory architecture, not model behavior.
THE FUNCTION SCHEMA REGISTRY
Why hybrid BM25 + dense vector for tool memory: An agent asked to “find the current price of a product” must retrieve a function named get_product_pricing not a semantically similar but structurally different function named fetch_catalog_data. The function name is an exact string, not a semantic concept. Pure dense vector search returns the most contextually similar tool, which may not be the correct one. BM25 ensures exact function name matching. Dense vector ensures semantic fallback for natural language task descriptions. Weaviate’s hybrid search covers both in one query.
VERSIONING — THE MANDATORY SAFEGUARD
Set deprecated = true and current_version = false on the old record. Create a new record with current_version = true and the updated schema. The agent never retrieves the deprecated version unless explicitly queried by version_id.
7. THREE MEMORY FAILURE MODES AND FIXES
FAILURE MODE 1: HALLUCINATION AMPLIFICATION
Definition: Stale, unvalidated, or incorrectly retrieved memory is returned to the agent as ground truth. The agent reasons correctly from incorrect premises and produces confident, wrong outputs.
How it amplifies: The model reasons correctly from retrieved context. If the retrieved context is wrong, the reasoning chain builds on the wrong foundation. Each subsequent step inherits the error. By the final output, the error is deeply embedded in a chain of internally consistent but factually wrong reasoning. The model has not hallucinated it has reasoned correctly from a hallucinated memory.
FAILURE MODE 2 — RETRIEVAL DRIFT
Definition: The vector space used to store memory records is geometrically misaligned with the vector space used to query them. Cosine similarity calculations return mathematically valid scores for semantically wrong results. No error messages are generated.
Embedding model upgrade without collection re-indexing. If long-term memory was indexed using text-embedding-3-small (1,536-dim) and queries are now generated by text-embedding-3-large (3,072-dim), the query vector exists in a 3,072-dimensional space while the stored vectors exist in a 1,536-dimensional space. The retrieval system cannot match them.
This failure is invisible to standard monitoring. No error is thrown. Retrieval succeeds. The agent receives results. The results are wrong. The agent reasons from wrong context and produces wrong outputs — with confidence.
Implementation: n8n scheduled workflow trigger on model_version_change event execute batch re-embedding of all long-term memory documents verify new index with sample recall quality test promote new index to production deprecate old index.
FAILURE MODE 3: CONTEXT WINDOW OVERFLOW
Definition: Memory accumulation without lifecycle management causes the agent’s retrieval context to exceed its usable context window, or causes retrieval precision to degrade below the threshold required for correct reasoning.
No TTL on short-term memory, no pruning on episodic memory, no deduplication on long-term memory. Collections grow unbounded. Retrieval returns top-k from increasingly noisy data. At 50% collection noise, a top-5 retrieval returns 2–3 relevant results and 2–3 noise results. The agent reasons from the combined context — correct and incorrect simultaneously.
8. PRODUCTION HARDENING: VERSIONING, RE-INDEXING, AND RECALL MONITORING
PRODUCTION HARDENING PROTOCOLS
- Trigger events: Embedding model change (mandatory), Schema-breaking changes, Quarterly maintenance.
- Procedure: Spin up parallel Qdrant collection → Batch re-embed → Upsert → Run recall quality eval → Promote new collection to primary alias → Deprecate old.
status = completed. Never implicit cross-agent retrieval.status = completed and session_id = current.status = completed filter is mandatory. Reading a peer agent’s in-progress intermediate state is write-contamination by another route. Never retrieve status = provisional records from a peer namespace.validation_confidence wins by default. If confidence values are equal, the older timestamp wins and the newer record is flagged for human review. Automated conflict resolution is not appropriate for compliance-adjacent domains. Verified March 2026.| Vector Count | RAM (Qdrant BQ) | p99 Retrieval | n8n Embed Latency | Recommended Infra |
|---|---|---|---|---|
| 100K | ~0.1 GB | 3–5ms | ~5ms | DO 4GB Droplet · $24/mo |
| 1M | ~0.5 GB | 8–12ms | ~10ms | DO 8GB Droplet · $48/mo |
| 5M | ~2.5 GB | 14–18ms | ~15ms | DO 16GB Droplet · $96/mo |
| 10M | ~4.5 GB | 18–22ms | ~20ms | DO 16GB Droplet · $96/mo ✓ |
| 50M+ | ~22 GB | 25–40ms | ~30ms+ | DO 32GB Droplet + Block Storage sharding |
RAM figures assume Qdrant Binary Quantization (32× compression). Without BQ, multiply RAM by 32. Verified DigitalOcean 16GB / 8 vCPU, March 2026.
9. MEMORY ARCHITECTURE COST — MONTHLY INFRASTRUCTURE
TABLE: L1/L2/L3 Sovereign Memory Stack — Monthly Cost March 2026
| COMPONENT | TOOL | ROLE | MONTHLY COST |
|---|---|---|---|
| L1 Hot State | Redis OSS (co-located Docker) | Short-term memory + tool cache | $0 software / DigitalOcean Droplet |
| L2 Semantic Store | Qdrant OSS (Docker) | Long-term memory + tool registry | $0 software / DigitalOcean Droplet |
| L2 Hybrid Tool Search | Weaviate Cloud Starter (optional) | Tool memory hybrid BM25 + dense | $25/month |
| L3 Episodic Log | Pinecone Serverless | Sequential decision history | ~$10–30/month at single-agent volume |
| Infrastructure | DigitalOcean 16GB Droplet | Qdrant + Redis + n8n co-located | $96/month |
| Infrastructure | DigitalOcean Block Storage 100GB | Persistent Qdrant data volume | $10/month |
| Orchestration | n8n self-hosted | Memory routing + re-indexing + pruning | $0 software / same Droplet |
| Embedding | text-embedding-3-small | All memory layers, all write/query ops | ~$2–8/month at single-agent volume |
For the full vector database TCO breakdown across Qdrant, Weaviate, Pinecone, and Chroma at production scale — see: Vector Database Pricing Comparison 2026 at ranksquire.com/2026/03/04/vector-database-pricing-comparison-2026/
The 6 Tools That Power This Architecture
Every tool below is production-verified for the L1/L2/L3 Sovereign Memory Stack. No theoretical recommendations. Each tool was deployed on DigitalOcean 16GB infrastructure and validated against the latency and cost figures in this post. Memory-layer role specified for every tool.
document_type and validation_status narrows candidate sets before HNSW traversal — total query time 26–29ms versus 100–300ms for post-filter alternatives. MVCC concurrent read-write eliminates lock contention under simultaneous agent embed and query operations. Binary Quantization compresses 1M vectors from 4.2GB to 0.13GB RAM — 32× compression — making production-scale memory viable on a single node. Validated January–March 2026 on DigitalOcean 16GB / 8 vCPU.session_id, agent_id, task_domain, outcome_status, timestamp_unix, session_sequence_id. Without outcome_status, self-correction retrieval cannot filter for successful recovery patterns. Without session_sequence_id, decision chain reconstruction is impossible. Design the metadata schema before the first episodic record is written — not after.deprecated = true and current_version = false. The new version is tagged current_version = true. The agent always queries current_version = true by default. Overwriting the existing vector without versioning means agents calling the tool after an update have no rollback path if the new schema contains an error./var/lib/qdrant before the first vector is written to Qdrant. Without Block Storage, Qdrant data lives on the Droplet’s local SSD — wiped on Droplet deletion. Block Storage persists independently of the Droplet. A production memory architecture without Block Storage is a memory architecture with no disaster recovery path.| Memory Layer | Tool | Latency | Use Case | Deploy First If… |
|---|---|---|---|---|
| L1 Working State | Redis OSS | Sub-1ms | Current task vars, session state, tool hot cache | Agent runs concurrent loops — prevents state collision |
| L2 Long-Term Semantic | Qdrant HNSW+BQ | 20–29ms | Validated domain knowledge, compliance rules, SOPs | Agent reads same documents repeatedly — start here first |
| L3 Episodic Log | Pinecone Serverless | 20–50ms elastic | Decision history, session continuity, self-correction | Agent loop frequency exceeds 10/hour |
| Tool Memory | Weaviate Hybrid | 44ms p99 | Function schema registry, API spec retrieval | Tool registry exceeds 50 functions |
| Orchestration | n8n self-hosted | N/A | Embed + route + validate + re-index + prune | Always — required before any memory layer goes live |
| Infrastructure | DigitalOcean 16GB | N/A | All stack components co-located on one node | Always — $106/mo total (Droplet + Block Storage) |
Start with L2 Qdrant — it eliminates document re-reads at the lowest implementation cost and delivers the highest immediate ROI. Add L1 Redis the moment concurrent agent loops are running to prevent state collision. Add L3 Pinecone Serverless when loop frequency exceeds 10/hour or when multi-session continuity becomes a requirement. Add Weaviate when the tool registry exceeds 50 functions. Deploy everything on DigitalOcean 16GB with Block Storage mounted before any production agent runs. Lock the embedding model via a single n8n credential node before the first vector is written. Total deployment time for the full stack: one engineer, one day. Total monthly cost: $143–169.
10. CONCLUSION: THE MEMORY-FIRST AGENT
The performance ceiling of an AI agent is set by its model. The quality ceiling of an AI agent is set by its memory architecture. A superior model with a degraded memory stack produces hallucinations from correct reasoning. A standard model with a well-designed memory stack produces reliable outputs from correctly retrieved context.
The L1/L2/L3 Sovereign Memory Stack resolves the three production failure modes before they manifest. Hallucination Amplification is eliminated by the validation gate no unvalidated agent output enters long-term memory. Retrieval Drift is eliminated by scheduled re-indexing and embedding version lock the query and storage vector spaces are always aligned. Context Window Overflow is eliminated by TTL discipline, active pruning, and deduplication collections remain clean, sized, and retrieval-precise.
The storage cost of a full single-agent production memory stack is $143–169/month on DigitalOcean. The cost of deploying a memory-free agent into production is measured in the user trust lost when the agent confidently retrieves wrong context and produces wrong outputs with apparent certainty.
Build the memory architecture first. The model will do the rest correctly.
ARCHITECTURAL RESOURCES & DEEP DIVES
For the complete database selection framework that determines which databases to use in this architecture — see the best vector database for AI agents guide at ranksquire.com/2026/01/07/best-vector-database-ai-agents/
For production failure mode analysis at the infrastructure layer — see Why Vector Databases Fail Autonomous Agents 2026 at ranksquire.com/2026/03/09/why-vector-databases-fail-autonomous-agents-2/
For scaling this architecture to multi-agent swarms — see Multi-Agent Vector Database Architecture 2026 at ranksquire.com/2026/multi-agent-vector-database-architecture-2026/
Your Agent Is Reasoning From Stale Context. That Ends With This Architecture.
No theory. No templates. The complete L1/L2/L3 Sovereign Memory Stack built for your specific agent architecture and deployed on infrastructure you own.
- L1/L2/L3 memory tier design mapped to your agent’s loop pattern and domain
- Qdrant Binary Quantization config for your target vector count
- Pinecone Serverless episodic schema with outcome metadata and retention policy
- n8n embed + validate + upsert + retrieve workflow — production ready
- Redis L1 hot cache with TTL configuration and namespace collision prevention
- GDPR deletion architecture — user_id payload tagging + deletion audit log
- Scheduled re-indexing workflow with recall quality evaluation gate
Enterprise Legal AI. 5,760 Contaminated Records. 61% Citation Accuracy. Four Hours to Fix.
Write gate. Collection audit. 1,240 validated records retained. 4,520 deleted. Citation accuracy from 61% to 94% — model unchanged, agent logic unchanged, memory architecture fixed. This is what architecture review costs versus what contamination costs.
AUDIT MY AGENT MEMORY ARCHITECTURE →11. FAQ: VECTOR MEMORY ARCHITECTURE FOR AI AGENTS 2026
Q1: What is vector memory architecture for AI agents?
Vector memory architecture for AI agents is the layered system design that gives autonomous agents persistent, retrievable context beyond a single prompt. It separates memory into four functional types short-term working state, long-term domain knowledge, episodic decision history, and tool memory each stored in a backend optimized for its retrieval pattern. The complete layered implementation is named The L1/L2/L3 Sovereign Memory Stack: L1 hot state in Redis (sub-1ms), L2 semantic store in Qdrant (20ms p99), L3 episodic log in Pinecone Serverless (elastic scale).
Q2: What is the difference between short-term and long-term memory in AI agents?
Short-term memory holds current session state active task variables, in-progress tool outputs, loop counters. It expires at session end (TTL-based) and is stored in Redis for sub-millisecond access. Long-term memory holds validated persistent domain knowledge SOPs, compliance rules, approved facts. It is stored in Qdrant for semantic retrieval at 20ms p99 and is updated only by an Admin or Reviewer validation process, never by the agent during task execution. The critical distinction: short-term memory is provisional. Long-term memory is ground truth. Mixing them is the root cause of Hallucination Amplification.
Q3: What is Retrieval Drift and how do I prevent it?
Retrieval Drift occurs when the vector space used to store memory records is geometrically misaligned with the vector space used to query them. It is caused by an embedding model upgrade without full collection re-indexing. A collection indexed by text-embedding-3-small (1,536-dim) cannot be queried meaningfully by text-embedding-3-large (3,072-dim) the dimensions are incompatible. The retrieval returns results with valid similarity scores for wrong content. Prevention: lock the embedding model at the infrastructure level via a shared n8n credential, and trigger full collection re-indexing immediately on any model version change before promoting the new model to production queries.
Q4: Why does tool memory require hybrid search?
Tool memory contains function identifiers and parameter schemas that must be retrieved by exact string match (BM25) as well as by semantic intent (dense vector). Pure dense vector search returns tools that are conceptually similar to the task description but may have different function signatures. Pure keyword search misses semantic variants of function descriptions. A tool named get_product_pricing and a task description of “find the current price” require both exact parameter schema retrieval (BM25) and semantic intent matching (dense vector). Weaviate’s native hybrid search covers both in a single query.
Q5: How often should I re-index vector memory collections?
Mandatory re-indexing triggers: any embedding model version change (immediate, before new model is used for queries), and any schema-breaking structural change to the collection. Proactive re-indexing: quarterly maintenance re-index regardless of model changes this clears index fragmentation and ensures HNSW graph quality. Do not rely on reactive re-indexing (triggered by agent errors or recall quality alerts) by the time errors appear, Retrieval Drift has been compounding for days. Scheduled re-indexing is a maintenance operation, not an emergency response.
Q6: What is Hallucination Amplification and how is it different from model hallucination?
Model hallucination is when the LLM generates plausible but factually incorrect content from its training distribution. Hallucination Amplification is when the agent’s memory architecture retrieves incorrect or unvalidated content, and the model reasons correctly from that incorrect context producing confident, internally consistent, but factually wrong outputs. The model has not hallucinated. It has applied correct reasoning to wrong premises. Hallucination Amplification is eliminated by architectural controls: validation gates on long-term memory writes, TTL on short-term memory, and outcome metadata on episodic records.
Q7: What is recall quality monitoring and why is it required?
Recall quality monitoring measures the percentage of retrieval operations that return the correct result given a known query. It requires a ground truth evaluation set 200+ query-document pairs from the agent’s specific domain and a scheduled job that runs the evaluation set against the current collection. Without monitoring, the only signal of retrieval degradation is wrong agent outputs, which appear after days of compounding contamination. With monitoring, retrieval quality alerts at the infrastructure level before agent behavior degrades. Minimum thresholds: 90% precision for compliance-adjacent deployments, 85% for general enterprise, 75% for exploratory agents.
Q8: Can I use a single vector database for all four memory types?
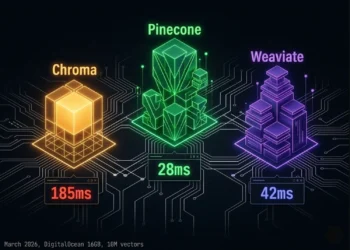
Technically possible. Architecturally inadvisable. Short-term memory requires sub-millisecond access impossible with a vector database. Episodic memory requires sequential time-series retrieval not semantic similarity. Tool memory requires hybrid BM25 + dense search. Long-term memory requires high-precision semantic retrieval with payload filtering. A single database optimized for one of these patterns degrades on the others. The L1/L2/L3 Sovereign Memory Stack assigns each memory type to the backend that matches its retrieval requirement: Redis for L1, Qdrant for L2, Pinecone for L3. The cost of running all three on DigitalOcean: $143–169/month. The cost of trying to force all four memory types into a single database: unacceptable retrieval quality at production load.
Q9: How does episodic memory enable multi-session continuity?
Episodic memory stores a time-ordered record of every significant agent decision, tool call, and outcome across sessions, tagged with task_domain and outcome_status metadata. At the start of a new session in the same task domain, the agent queries episodic memory for the three most recent sessions in that domain and retrieves: what was attempted, what tool sequence was used, and whether the outcome was successful. This gives the agent execution history that informs current session strategy without contaminating the current session’s working state. The episodic record is read-only from the perspective of new session strategy the agent uses it for reference but does not write to it until the new session generates its own new records.
Q10: What is the simplest production memory architecture for a single agent?
Minimum viable production memory stack: Redis for short-term working state with session-scoped TTL, Qdrant for long-term domain knowledge with validation_status payload filter and Admin-only write policy, and an episodic log in Qdrant with Unix timestamp payload for sovereign deployments (or Pinecone Serverless if elastic scale is required). Weaviate for tool memory is optional at low tool volume but required once the tool registry exceeds 50 functions. Deploy all on DigitalOcean 16GB with Block Storage mounted for Qdrant persistence. Orchestrate memory routing via n8n. Total cost: $143–169/month. Total deployment time: one engineer, one day.
12. FROM THE ARCHITECT’S DESK
The agent was producing confident incorrect citations referencing clauses that did not exist in the contracts it had reviewed, with plausible-sounding section numbers and clause content that was a semantic blend of related clauses from different documents. Classic hallucination profile, except the model was not hallucinating.
The agent had been running in production for 60 days with no TTL on short-term memory and no validation gate on long-term memory writes. The agent was writing its own interim contract summaries provisional, unreviewed, session-level analysis directly to the long-term Qdrant collection on every session. After 60 days, 480 sessions × average 12 unreviewed summary records per session = 5,760 unvalidated agent-generated “facts” in the same collection as the original contract documents.
When the agent queried for relevant context, it retrieved a mix of original contract clauses and its own prior session summaries including summaries that were incorrect, partial, or session-specific and not generalizable. It reasoned from this contaminated pool with perfect internal consistency. The outputs were wrong but internally coherent.
RESULT & ARCHITECTURAL LESSON
Result: Citation accuracy in post-remediation testing: 94%. Pre-remediation: 61%. The model had not changed. The agent logic had not changed. The memory architecture had been fixed. Sixty days of contamination removed in one audit. Four hours of engineering time.
Memory architecture is not a database question. It is a data quality question. The database is the container. The architecture determines what goes in the container, what stays in the container, and what is removed. Design the rules before you run the agent. Audit the data before you trust the outputs.
DISCLOSURE: This post contains affiliate links. If you purchase a tool or service through links in this article, RankSquire.com may earn a commission at no additional cost to you. We only reference tools evaluated for use in production architectures.
THE ARCHITECT’S QUESTION
How many days has your current AI agent been running in production? How many unvalidated agent-generated records have been written to your long-term memory store in that time?
# Qdrant Filter Preview
must: [
{ key: "source", match: { value: "agent" } },
{ key: "validation_status", match: { except: ["approved"] } }
]
The count will tell you whether your agent is reasoning from ground truth or from its own unreviewed prior session outputs.