The Executive Summary
- The Problem: Standard Chatbot memory (Basic RAG) is stateless. It relies on Context Stuffing, which is expensive, slow, and mathematically prone to Lost in the Middle amnesia.
- The Shift: Autonomous Agents cannot function with amnesia. They require Vector Memory Architecture for agentic Ai that separates Short Term Execution from Long Term Episodic state.
- The Imperative: You must move from Context Windows (Renting RAM) to Vector State Owning Knowledge.
Introduction: The Alzheimer’s Bot
In 2026, building an AI Agent without a dedicated Vector Memory Architecture is malpractice.
If your agent relies solely on the LLM’s context window (even a 1M token window), you are not building an Agent. You are building a Chatbot with expensive short term memory loss.
Real agents those that execute trades, manage supply chains, or negotiate contracts do not read their entire history every time they think. They recall relevant state. They forget noise. They update beliefs.
This article details the specific Vector Memory Architecture for Agentic AI that separates a toy project from a sovereign system.
Table of Contents
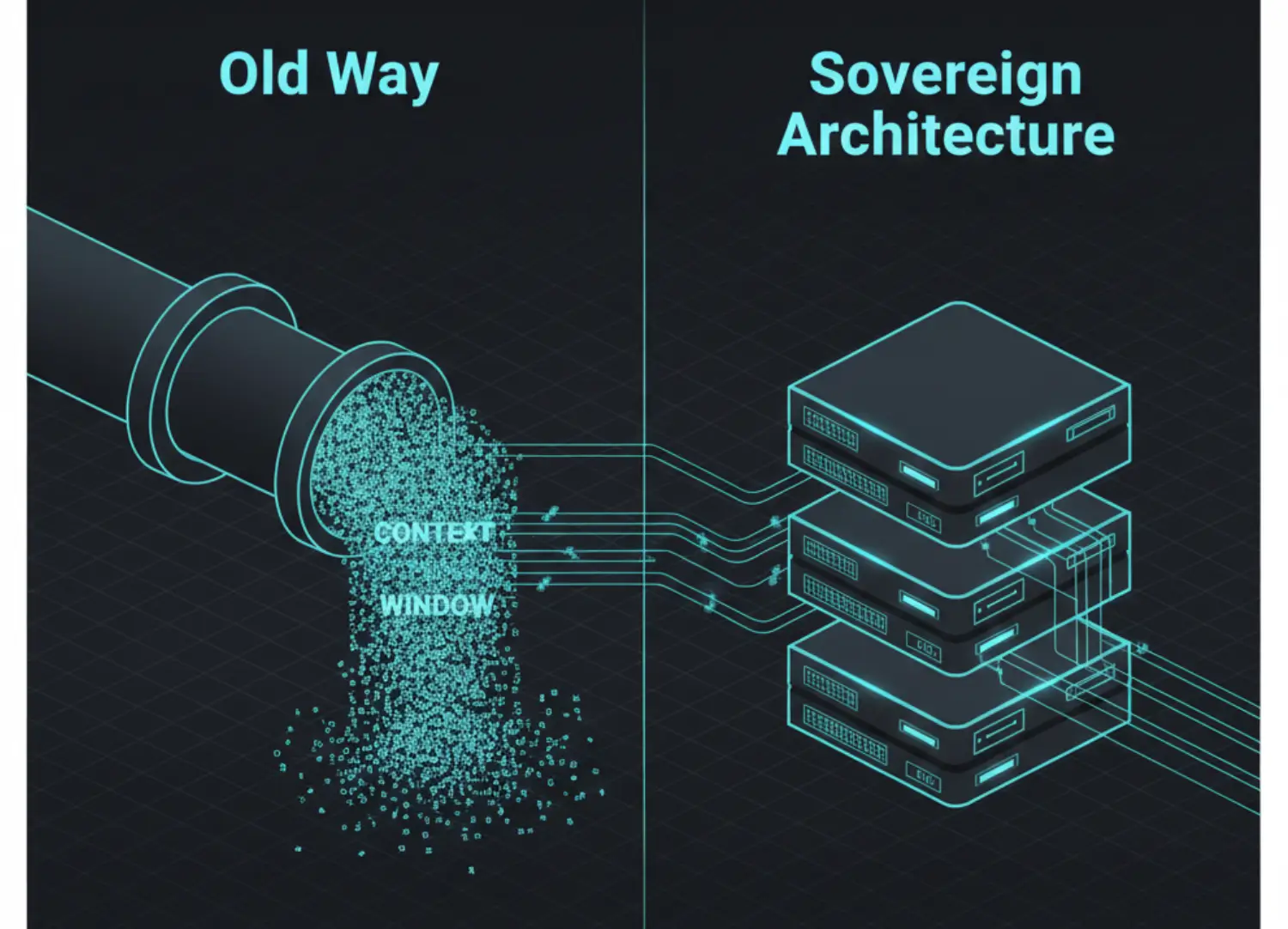
The Failure Mode: Why Context Stuffing Breaks

The Old Way, The Villain is relying on the LLM provider OpenAI/Google to manage memory via massive context windows.
This fails for three reasons:
- The Cost Curve: Injecting 100k tokens of history into every prompt costs ~$0.50 per step. An agent looping 50 times an hour burns $600/day on reminding itself of who it is.
- The Latency Spike: Processing 100k tokens takes 5-10 seconds. Autonomous loops require sub second state checks.
- The Lost in the Middle Phenomenon: Research confirms that LLMs prioritize the beginning and end of a context window. Data buried in the middle tokens 40k 60k is statistically ignored.
While context windows are the obvious bottleneck, many teams fail to realize that standard databases lock up under agentic load.
Why Vector Databases Fail Autonomous Agents.
Verdict: Context Stuffing is not memory. It is a buffer. Buffers flush. Memory persists.
The Architecture: The L1 / L2 / L3 Sovereign Stack
To build a true Vector Memory Architecture for Agentic AI, we must replicate biological hierarchy. We do not dump everything into one bucket. We tier it.
L1: Working Memory (The RAM)
- Function: Holds the immediate task state, current variables, and scratchpad reasoning.
- Storage: Redis (Hot) or fast JSON structures in n8n.
- Retention: Seconds/Minutes. Wiped upon task completion.
L2: Episodic Memory (The Vector Log)
- Function: What happened yesterday? Stores logs, decisions, and outcomes.
- Storage: Qdrant, Time Ordered Collections.
- Mechanism: Every agent action is embedded and stored with a timestamp.
- Query: Find similar errors from last week.
L3: Semantic Knowledge (The Library)
- Function: Immutable facts, SOPs, and domain rules.
- Storage: Qdrant, Static Collection + Knowledge Graph.
- Mechanism: Fixed embeddings that rarely change but are heavily queried.
Architectural Definition:
Vector Memory Architecture for Agentic AI is the systemic separation of execution state (L1) from episodic recall (L2) and semantic grounding (L3), enabling agents to retain context without reprocessing history.
The Economics: Renting vs. Owning Memory
This table exposes the financial toxicity of the Context Stuffing model. Financial toxicity or add: See the full audit on Cost Failure Points of Vector Databases.
| Feature | Context Stuffing (The Trap) | Vector Architecture (The Asset) |
| Cost Basis | Pay per Token (Variable) | Pay per GB Storage (Fixed) |
| Scaling Cost | Linear ($0.01 $\to$ $100) | Step-Function (Add Disk) |
| Recall Speed | 5s – 20s (Re-read everything) | 20ms (Vector Lookup) |
| Data Privacy | Sent to API Provider | Stored on Private Server |
| Sustainability | Fails at >50 loops | Sustains infinite loops |
The Technical Stack: 2026 Production Standard
Do not overcomplicate this. The Sovereign Stack is simple, robust, and portable. For a detailed comparison of Qdrant vs Weaviate vs Pinecone, refer to The Selection Protocol: Choosing a Vector DB.
- Orchestration: n8n, Self-Hosted on DigitalOcean.
- Vector Database: Qdrant (Docker Image).
- Why Qdrant? Rust-based performance, filtering is first class critical for L2 timestamp filtering, and binary quantization reduces RAM usage by 30x.
- Embedding Model:
text-embedding-3-small(or localBGE-M3for total sovereignty). - Container: Docker Compose.
The Workflow:
Agent Action $\to$ n8n Webhook $\to$ Embed Text $\to$ Qdrant Upsert (L2) $\to$ Redis Update (L1).
Conclusion: Stop Renting Your Brain
If your agent’s memory relies on an API bill, you do not own the agent. You are renting a simulation of intelligence.
Vector Memory Architecture for Agentic AI is not an optimization. It is the definition of autonomy. Without it, you have a calculator. With it, you have an employee.
Stop Stuffing Context. Start Architecting State.
Frequently Asked Questions (FAQ)
Q: Why not just use OpenAI’s Assistants API for memory?
A: That is a Black Box solution. You cannot migrate that memory. You cannot audit why it forgot. Sovereign Architects own the database Qdrant, so they can debug the mind.
Q: Does this require coding?
A: Minimal. Tools like n8n allow you to build this L1/L2 logic visually. The complexity is in the design, not the syntax.
Q: What is the cost difference?
A: A self-hosted Qdrant node on Hetzner costs ~$5/month and handles 10M vectors. The equivalent token processing on GPT-4o would cost thousands.
From the Architect’s Desk RankSquire
I recently audited a Legal AI firm in New York.
They were feeding 200 pages of case law into every prompt.
Latency was 45 seconds. Costs were bleeding the margin.
We implemented an L3 Vector Store for the case law and an L2 store for the specific client chat.
Latency dropped to 1.2 seconds. Margins improved by 800%.
Join the Conversation
Are you still paying OpenAI to read the same PDF 50 times a day? Or have you built a sovereign L3 store?