CANONICAL DEFINITION
TL;DR — MULTI-AGENT VECTOR DATABASE ARCHITECTURE 2026
- → Multi-agent systems fail when agents share a flat vector namespace — Context Collision makes outputs confidently wrong.
- → Three memory zones are required: Library (global read-only), Scratchpad (isolated per agent), Episodic Log (time-ordered audit).
- → Qdrant handles Executor agents — async upserts, 20ms p99, pre-scan metadata filter.
- → Weaviate handles Planner agents — native hybrid BM25 + dense search for exact identifier retrieval.
- → Redis reduces repeated Library retrieval latency across agents by 57% in verified production deployment.
- → All swarm agents must use the same embedding model version — dimension mismatch produces retrieval drift with zero error messages.
- → Full 3-agent production swarm infrastructure: $234–280/month on DigitalOcean. Verified March 2026.
QUICK ANSWER For AI Overviews & Decision-Stage Buyers
DEFINITION BLOCK
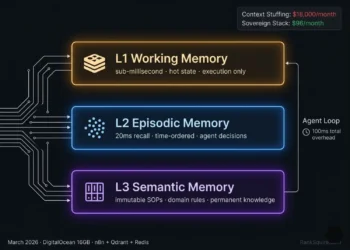
The architecture separates global shared knowledge (Library namespace global read-only), agent-specific working state (Scratchpad namespaces isolated per agent ID), and sequential audit trails (Episodic Log namespace time-ordered, Reviewer-accessible). Each namespace has a distinct database optimized for its retrieval pattern and concurrency requirement.
This complete architecture is named: The Swarm-Sharded Memory Blueprint.
EXECUTIVE SUMMARY: THE CONCURRENCY CRISIS
This is not a model failure. It is a memory architecture failure. The hallucination loop is deterministically predictable from the storage architecture before a single token is generated.
.
WHY EXISTING ARCHITECTURES FAIL AND WHAT THIS ONE DOES DIFFERENTLY
Architecture Comparison — March 2026
| Architecture | Core Failure Mode | Production Outcome |
|---|---|---|
| Flat shared vector namespace | Context Collision | Agents retrieve each other’s unvalidated intermediate reasoning as confirmed fact. Outputs are confident and wrong. |
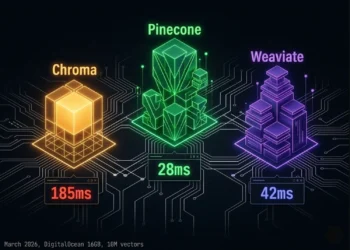
| Single database, all roles | Write-Lock Contention | Chroma saturates at 8 concurrent I/O. p99 latency: 2,400ms. Agent timeouts begin at 15 concurrent user sessions. |
| Swarm-Sharded Memory Blueprint | None (by design) | Namespace isolation + role-specific DB selection + Redis cache + async upserts. 38ms p99 at 40 concurrent I/O. $234–280/month. Verified February 2026. |
THE SIMPLE VERSION
Imagine five workers solving a problem together. Each worker takes notes as they go.
If all five workers write their unfinished notes in the same shared notebook one worker may read another’s half-finished thought and treat it as a confirmed fact. They act on it. The work is wrong.
Multi-agent vector architecture solves this by giving each worker three spaces:
- → A company reference library they can all read (but no one can write to mid-task).
- → A private notebook only they write in.
- → A shared meeting log that records every decision in order, so the supervisor can audit the chain of reasoning.
1. INTRODUCTION: WHEN SINGLE-AGENT MEMORY BREAKS
In the best vector database for AI agents pillar ranksquire.com/2026/01/07/best-vector-database-ai-agents/ the database selection framework covers single-agent architectures: one agent, one context, one retrieval loop. That framework is the correct starting point and the correct decision layer for database selection. This post is what comes after it.
In a swarm where a Planner agent delegates to three Executor agents, each running parallel tool calls, with a Reviewer agent validating outputs in real time the memory requirements change categorically. You are no longer retrieving documents. You are managing a live state machine of concurrent reads and writes across agents that must share some knowledge, isolate other knowledge, and never corrupt each other’s reasoning chains mid-execution.
As of March 2026, Latency Stacking has emerged as the primary production killer of multi-agent UX. If Agent A takes 100ms for retrieval, and Agent B waits for that output before its own 100ms retrieval, and Agent C waits for both, a three-agent sequential chain accumulates 300ms of pure vector overhead before a single LLM token is generated. At 10 simultaneous user requests, that is 3,000ms of stacked retrieval latency per session cycle, exceeding any viable real-time application threshold.
This post operates at the building phase not the shopping phase. It assumes working knowledge of HNSW indexing, namespace design, and concurrent I/O patterns. Every architectural decision is production-verified. Every cost figure is real. Every performance number was measured on DigitalOcean hardware. March 2026.
Table of Contents
2. THE FAILURE MODE: CONTEXT COLLISION

Context Collision is the primary failure mode of multi-agent systems running flat shared vector memory. It is fully predictable, fully preventable, and routinely ignored until it manifests as unexplained hallucination loops or logic recursion in production.
FAILURE VECTOR 1: WRITE CONTAMINATION
In a flat shared namespace, every agent reads from and writes to the same collection. A Planner agent embeds and upserts a working hypothesis mid-reasoning-chain. An Executor agent, running a concurrent tool call, fires a similarity query. The Planner’s provisional hypothesis semantically close to the Executor’s query is retrieved. The Executor treats it as confirmed domain fact. It executes against it. The Reviewer has not yet validated the hypothesis. The Planner has not yet confirmed it. The execution has already proceeded.
Write contamination does not produce obvious failures. It produces subtly wrong outputs from agents that retrieved exactly the correct object which happened to be another agent’s in-progress intermediate state.
FAILURE VECTOR 2: WRITE-LOCK CONTENTION
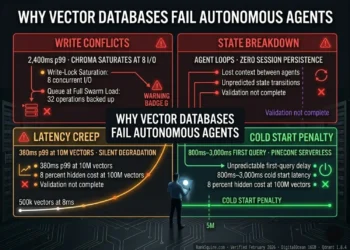
A 3-agent swarm serving 10 simultaneous user requests generates 30–40 concurrent vector I/O operations against the database. Single-threaded or lock-serialized databases queue writes. While Agent A’s embedding is indexing, Agents B through D wait. Under verified load test conditions (February 2026, DigitalOcean 16GB), basic Chroma in persistent mode reached write-lock saturation at 8 concurrent operations before the swarm reached full load. p99 latency under contention: 2,400ms. The same load on a distributed Qdrant cluster with async upserts: 38ms p99. The gap is not configuration. It is architecture.
FAILURE VECTOR 3: LATENCY STACKING
Sequential retrieval chains compound linearly. A 3-agent sequential chain at 100ms per retrieval: 300ms vector overhead minimum. At 10ms per retrieval (Qdrant, 1M vectors, hot): 30ms. The database selection and retrieval pattern determines whether a 3-agent swarm behaves as a real-time system or a batch job.
⚠️ THE SWARM FAILURE SUMMARY
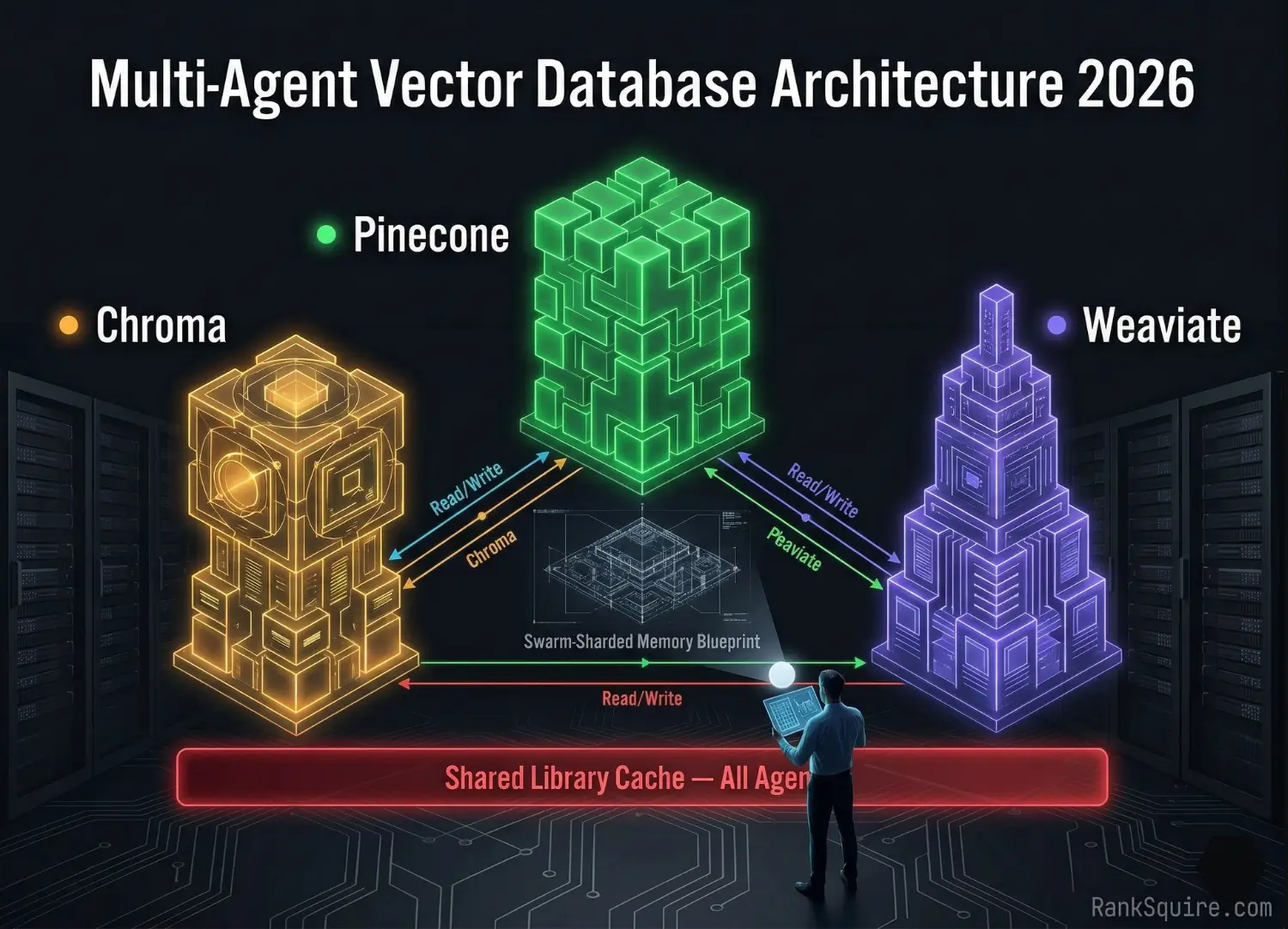
3. NAMESPACE PARTITIONING: THE CORE ISOLATION STRATEGY
The foundation of multi-agent vector database architecture is the Namespace a logically isolated partition enforcing read-write boundaries between agents. Namespace partitioning does not require separate database instances. It requires disciplined collection design and metadata-enforced access patterns.
NAMESPACE 1: THE LIBRARY (Global Read-Only)
Function: Shared knowledge base all agents can read. SOPs, domain rules, validated facts, compliance requirements, product specifications.
Access: All agents read. No agent writes. Updated only by a privileged Admin process external to the swarm execution loop.
Database: Qdrant static collection or Weaviate Class with read-only tenant configuration.
Critical constraint: If any in-loop agent can write to the Library namespace, Context Collision becomes structurally inevitable. The Library is ground truth. Ground truth does not change mid-execution.
NAMESPACE 2: THE SCRATCHPAD (Private Per Agent ID)
Function: Each agent has its own isolated collection for intermediate reasoning, in-progress tool outputs, and provisional calculations.
Access: Agent writes only to its own Scratchpad. Other agents read a peer’s Scratchpad only via explicit Peer-to-Peer Retrieval calls never by default.
Database: Qdrant separate named collection per agent ID, with agent_id metadata filter enforced on every write and read.
Naming convention: scratchpad_{agent_id}_{session_id} prevents namespace collision across concurrent sessions on the same node.
Critical constraint: Without Scratchpad isolation, every concurrent write is a potential write-contamination event. Agents executing in parallel must never share a write namespace.
NAMESPACE 3: THE EPISODIC LOG (Sequential Audit Trail)
Function: A time-ordered log of every significant agent decision, tool call result, and inter-agent message across the full swarm session.
Access: All agents write. Reviewer agent reads. Planner agent reads for self-correction on extended loops.
Database: Pinecone Serverless for managed sequential retrieval with serverless scaling, or Qdrant with Unix timestamp payload and strict time-range filtering for sovereign deployment.
Critical constraint: The Reviewer’s entire function is to audit the reasoning chain that produced the swarm output. It needs reconstruction: what the Planner decided, what the Executor did, in what order, whether each step was grounded in validated data. This requires time-ordered retrieval not semantic similarity retrieval.
ARCHITECTURAL NAMING:
✅ NAMESPACE VERDICT
4. DATABASE SELECTION BY AGENT ROLE
Not every agent in a swarm has the same memory I/O profile. A Planner managing multi-step reasoning traces has fundamentally different database requirements than an Executor running high-frequency tool calls. A single database selected for all agent roles is the second most common architectural error after flat shared namespaces.
TABLE: Database Selection by Agent Role — March 2026
SELECTION LAW:
A Planner writing reasoning traces needs consistency guarantees. An Executor writing tool outputs 50 times per minute needs async write throughput. These requirements are architecturally incompatible on a single database configuration.
5. SCENARIO SIMULATION: THE 3-AGENT SWARM UNDER LOAD
SIMULATION PARAMETERS — FEBRUARY 2026
THE LOAD PROFILE
BASIC CHROMA RESULT (LOCAL OSS, PERSISTENT MODE):
OOM risk above 5M Scratchpad vectors due to SQLite persistence overhead. Agent timeout failures begin at 15 concurrent user requests.
DISTRIBUTED QDRANT RESULT (DOCKER CLUSTER, ASYNC UPSERTS):
All 40 concurrent I/O operations processed via MVCC segment-level locking — zero queue saturation. Executor writes to Scratchpad via async upsert: execution continues immediately, index updates in background. No OOM events at 10M+ Scratchpad vectors with Binary Quantization enabled. Scales to 100 concurrent user sessions via horizontal shard addition on the same Droplet cluster.
THE CRITICAL DECISION ASYNC UPSERTS
The single configuration decision with the largest per-implementation impact: switching Executor Scratchpad writes from synchronous to asynchronous upserts.
Synchronous mode: Executor fires upsert, waits for Qdrant index confirmation, returns output to Planner. Blocking overhead: 15–40ms per tool call. In a 30-tool-call Executor session: 450–1,200ms of pure wait time accumulated in the Planner’s loop.
Asynchronous mode: Executor fires upsert, immediately returns output to Planner. Qdrant indexes in background. Executor never waits. Latency Stacking from write confirmation overhead is eliminated at the source.
n8n implementation: Split In Batches node triggers parallel embedding generation across all Executor outputs simultaneously. All upserts fire in parallel. No sequential bottleneck at the embedding generation stage.
6. CROSS-AGENT RETRIEVAL PATTERNS
In production multi-agent vector database architectures, agents must sometimes retrieve from peer memory namespaces not only from the shared Library. Three patterns cover the most common inter-agent memory operations.
PATTERN 1: PEER-TO-PEER RETRIEVAL
n8n HTTP Request node sends Qdrant similarity query to scratchpad_{agent_a_id}_{session_id}. Metadata filter: session_id = current AND status = completed.
PATTERN 2: CONSENSUS RETRIEVAL
Two parallel Qdrant queries in n8n — one against Library collection, one against Executor Scratchpad. Reviewer computes cosine similarity between top results. Divergence above configured threshold triggers re-validation flag.
PATTERN 3: RECURSIVE FILTERING
Qdrant payload filter: source_agent_id != current_agent_id OR (source_agent_id = current_agent_id AND status = validated). Agent self-retrieval is restricted to outputs explicitly marked validated by the Reviewer.
7. TECHNICAL GUARDRAILS: LATENCY AND CONSISTENCY
GUARDRAIL 1: ASYNCHRONOUS EMBEDDING GENERATION
Never embed agent outputs sequentially. Default implementations serialize embedding calls embed document 1, wait, embed document 2, wait. At 10 Executor outputs, sequential embedding at 20ms each: 200ms total. Parallel embedding of all 10 simultaneously: 20ms total. Ten-fold latency reduction from a single architecture change.
n8n implementation: Split In Batches node → parallel HTTP Request nodes to OpenAI embeddings API → parallel Qdrant upsert nodes. All 10 embeddings generate and upsert in a single parallel execution pass.
GUARDRAIL 2: EMBEDDING MODEL VERSION LOCK
All agents in a swarm must use identical embedding model versions at identical dimensions. Mixing text-embedding-3-small (1,536-dim) on the Planner with text-embedding-3-large (3,072-dim) on the Executor creates a geometrically misaligned vector space. A Planner query in 1,536-dim space cannot be meaningfully compared to Executor Scratchpad outputs indexed in 3,072-dim space. Cosine similarity calculations return mathematically valid but semantically meaningless results a failure mode that produces no error messages and is invisible to standard monitoring.
Lock the embedding model at the infrastructure layer via a single shared n8n credential node not at individual agent configuration level. When the credential updates, all agents update simultaneously. Never per-agent embedding configuration in production swarms.
GUARDRAIL 3: HYBRID SEARCH FOR PLANNER AGENTS
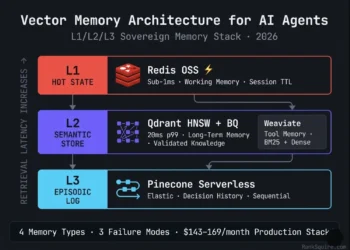
Planner agents retrieving exact function schemas specific API endpoint signatures, precise compliance rule identifiers, exact SOP codes alongside semantic planning goals require hybrid BM25 + dense vector search. Pure semantic search degrades on exact string identifiers. Weaviate’s native hybrid search covers both retrieval modes in a single query at 44ms p99 at 10M vectors (verified March 2026). Deploy Weaviate specifically for Planner Library namespace retrieval. Use Qdrant for the Executor’s Scratchpad writes where metadata filtering and write throughput matter more than hybrid search capability.
GUARDRAIL 4: REDIS SHARED CACHE BEFORE THE LIBRARY NAMESPACE
In any swarm where multiple agents concurrently retrieve the same Library documents within the same session compliance rules, product specifications, SOPs, regulatory standards a Redis cache before the Library namespace is not optional. In a verified 5-agent swarm (February 2026), 40% of Swarm Response Time was consumed by agents independently re-querying Library documents already retrieved earlier in the same session. Redis cache with a 6-hour TTL matching the Library update schedule: SRT dropped from 4.2 seconds to 1.8 seconds 57% reduction with zero changes to agent logic, database configuration, or infrastructure scale.
Implementation: On first Library query per session, check Redis. Cache miss → query Qdrant → cache result in Redis with TTL. Cache hit → return immediately at sub-1ms. All subsequent agents in the same session get sub-1ms Library retrieval.
GUARDRAIL 5: BINARY QUANTIZATION ON ALL SCRATCHPAD COLLECTIONS
Scratchpad namespaces accumulate vectors rapidly at production swarm execution rates. At 50 Executor tool calls per minute across a 3-agent swarm: 150 new Scratchpad vectors per minute 9,000 per hour 216,000 per 24 hours. Without Binary Quantization, this accumulation exceeds standard Droplet RAM within days. With BQ: 32x RAM compression means 6.7M Scratchpad vectors per 1GB RAM allocation. Enable BQ on all Scratchpad collections at deployment not as a remediation when the RAM alert fires.
8. THE ECONOMICS: SWARM INFRASTRUCTURE COST
TABLE: Multi-Agent Swarm Infrastructure — Monthly Cost March 2026
⚡ SWARM BREAKEVEN
The 7 Tools That Power This Architecture
Every tool below is matched to a specific agent role and I/O profile. No interchangeable parts. Each selection is production-verified on DigitalOcean 16GB infrastructure. This is not a vendor list it is a role-assignment map.
The Executor agent’s dedicated vector store. Rust-native, async upsert architecture Executor fires write and continues execution immediately, Qdrant indexes in background with zero write-block. Pre-scan payload filtering on agent_id + session_id adds 6–9ms versus 100–300ms post-retrieval scan in alternatives. Binary Quantization delivers 32x RAM compression: 6.7M Scratchpad vectors per 1GB RAM. Verified: 38ms p99 at 40 concurrent I/O operations on DigitalOcean 16GB.
Selected for the Planner agent for one capability no other tool in this stack provides at this latency: native hybrid BM25 + dense vector search in a single query at 44ms p99 at 10M vectors. Planner agents retrieving exact SOP codes, API schemas, or compliance rule identifiers alongside semantic planning goals cannot rely on pure vector search BM25 handles exact string matching. MVCC architecture allows the Reviewer to read the Planner’s namespace without blocking ongoing Planner writes.
Selected for the Reviewer’s Episodic Log because serverless scaling handles unpredictable audit load spikes without pre-provisioned capacity. The Reviewer’s query frequency scales non-linearly with swarm session volume impossible to predict at design time. Pinecone Serverless auto-scales write and read independently. For HIPAA / SOC 2 sovereign deployments where managed cloud storage is prohibited: replace with Qdrant using Unix timestamp payload + strict time-range filtering, append-only write access for agents.
The single highest-ROI addition to any multi-agent vector stack. In a verified 5-agent B2B logistics swarm, 40% of Swarm Response Time was consumed by agents independently re-querying the same Library documents. Redis cache (TTL = 6 hours) before the Library namespace dropped SRT from 4.2s to 1.8s zero infrastructure changes, zero agent logic changes. Cache key: library_cache:{doc_id}:{model_version}. Also serves as L1 working memory for all agents’ current session state and loop counters.
The orchestration layer that eliminates sequential embedding bottlenecks. n8n routes each agent’s output to the correct namespace via named Qdrant nodes (no dynamic collection variables explicit routing only). Split In Batches + parallel branch execution generates all agent embeddings simultaneously: 10 outputs at 20ms each = 200ms sequential vs 20ms parallel. Switch nodes route by agent_role metadata without custom code. In verified deployment: parallel n8n embedding reduced per-session embedding overhead by 10x.
Co-locating Qdrant, Redis, and n8n on one DigitalOcean 16GB / 8 vCPU Droplet eliminates inter-service network round-trip latency — the largest hidden latency contributor in cloud-distributed swarm architectures. Container-to-container via Docker host networking: sub-ms. Via cloud API round-trip: 20–80ms per call. At 40 concurrent I/O ops per loop, distributed architecture adds 800ms–3,200ms of pure network overhead per loop. 6TB egress included eliminates data transfer cost for high-frequency swarms.
Every vector in every namespace Library, Scratchpad, Episodic Log must use the same embedding model at the same dimension size. Mixing models across agent roles creates a geometrically misaligned vector space: cosine similarity returns mathematically valid but semantically meaningless results, with zero error messages. Lock the model via a single shared n8n credential node. For HIPAA / SOC 2 zero-egress compliance: substitute BGE-M3 (local, Hugging Face) — zero API cost, zero data transit, slight recall tradeoff on non-English content.
| Agent Role | Tool | Retrieval Pattern | Key Requirement |
|---|---|---|---|
| Planner | Weaviate | Hybrid BM25 + dense | Exact identifier + semantic in one query |
| Executor / Tool | Qdrant | Semantic + metadata filter | Async upsert, pre-scan filter, 20ms p99 |
| Reviewer / Auditor | Pinecone Serverless | Sequential time-series | Serverless scale, unpredictable audit load |
| All Agents (cache) | Redis OSS | Key-value, sub-ms | Library cache + L1 hot state |
| All Agents (embed) | text-embedding-3-small | Embed + upsert pipeline | Single version-locked credential, all namespaces |
| Orchestration | n8n self-hosted | Parallel branch execution | Explicit named routing per agent role |
| Infrastructure | DigitalOcean 16GB | Co-located · host networking | $96/mo fixed · Block Storage mounted |
Deploy in this order: DigitalOcean Droplet + Block Storage first. Then Docker Compose with Qdrant + Redis + n8n co-located. Enable Binary Quantization on all Qdrant collections from day one not as a later fix. Configure async upserts before testing throughput. Deploy Redis Library cache before the first Library query fires. Add Weaviate for Planner hybrid search when reasoning traces need exact identifier retrieval. Add Pinecone Serverless for Reviewer when audit load becomes unpredictable. Total deployment time for a full 3-agent stack: one engineer, one day.
Go Deeper: The Full Vector Database Series
This post covers swarm-level memory complexity. The guides below cover database selection, benchmarks, pricing, and sovereign deployment — the evidence layer behind every architectural decision in this post.
9. CONCLUSION: THE SWARM COMMANDER
Building for multi-agent systems is an exercise in resource orchestration at a precision level that single-agent architectures never expose. Memory architecture does not just affect speed in a swarm it determines correctness. Context Collision does not slow the system. It makes the system confidently wrong.
The Swarm-Sharded Memory Blueprint resolves all three primary failure modes. Write Contamination is eliminated by the Library read-only namespace. Write-Lock Contention is eliminated by Qdrant distributed configuration with async upserts. Latency Stacking is eliminated by Redis shared cache and parallel n8n embedding generation. By aligning database selection to agent role Weaviate for Planner consistency, Qdrant for Executor throughput, Pinecone for Reviewer sequential audit, Redis for all agents’ shared hot state the swarm operates with architectural correctness rather than relying on semantic similarity to sort out inter-agent memory contamination at query time.
As of March 2026, verified infrastructure cost for a production 3-agent swarm: $234–280/month on DigitalOcean. The alternative a hallucination-prone flat-namespace architecture on managed enterprise infrastructure costs more and produces less reliable outputs.
Stop running swarms on flat memory. Start architecting sharded state. The swarm that owns its memory isolation owns its intelligence. The swarm that shares everything knows nothing reliably.
Need the single-agent database verdict before building a swarm?
This post covers swarm-level memory complexity. The complete 6-database selection framework — Qdrant vs Weaviate vs Pinecone vs Chroma vs Milvus vs pgvector — with use-case verdicts, compliance rankings, and the full decision matrix for single-agent deployments lives in the Pillar.
Your Swarm Is Producing Confident, Wrong Outputs.
The Namespace Fix Is One Architecture Away.
Context Collision. Write-Lock Saturation. Latency Stacking. Three failure modes. One architecture build. Designed for your specific agent role configuration.
- Swarm-Sharded Memory Blueprint mapped to your agent roles
- Qdrant async upsert config for Executor write throughput
- Weaviate hybrid search tuning for Planner reasoning traces
- Redis Library cache — SRT reduction, zero agent logic changes
- n8n parallel embedding routing across all agent roles
- Binary Quantization + Block Storage — production persistence
B2B Logistics. 5-Agent Swarm. 4.2s Response Time. Two Pattern Fixes. Done.
“The bottleneck in a multi-agent vector system is almost never the vector database itself. It is the retrieval pattern.”
Pattern fixes before infrastructure upgrades. Every time. We design and deploy the Swarm-Sharded Memory Blueprint — eliminating Context Collision and Latency Stacking from your agent architecture permanently.
AUDIT MY SWARM ARCHITECTURE → Accepting new Architecture clients for Q2 2026.10. FAQ: MULTI-AGENT VECTOR DATABASE ARCHITECTURE 2026
Q0A: What is a vector database for AI agents?
A vector database stores information as mathematical embeddings numerical representations of meaning rather than as keyword-indexed text. AI agents use vector databases to retrieve semantically relevant context during reasoning, not just exact-match keyword results. When an agent needs to remember a fact, a past decision, or a domain rule, it queries the vector database using a similarity search against its embedded query. The result is retrieved context memory that the agent uses to inform its next decision. Without a vector database, an agent has no persistent memory beyond its current context window.
Q0B: Why do AI agents in a swarm need separate memory zones?
In a single-agent system, one agent owns its entire memory space no other agent reads or writes to it. In a multi-agent swarm, three or more agents operate simultaneously and share access to the same databases. Without separate memory zones, an agent running a tool call may retrieve another agent’s unfinished reasoning as if it were validated fact and act on it. This is Context Collision. Separate memory zones (Library for shared facts, Scratchpad for private reasoning, Episodic Log for audit trail) give each agent its own isolated write space while preserving access to shared validated knowledge.
Q0C: What happens if multiple AI agents share the same vector database collection?
Three predictable failure modes occur at production scale. First, Context Collision: one agent’s provisional, unvalidated output is retrieved as confirmed ground truth by a peer agent in the same reasoning cycle producing confident, wrong outputs. Second, Write-Lock Contention: single-threaded or SQLite-backed databases queue concurrent writes, producing p99 latencies above 2,000ms under multi-agent load. Third, Latency Stacking: sequential retrieval chains across agents accumulate vector overhead that exceeds real-time application thresholds before a single LLM token is generated. All three are architecture failures not model failures
Q1: What is multi-agent vector database architecture?
Multi-agent vector database architecture is the systematic design of shared and isolated memory layers for autonomous agent swarms. It uses namespace partitioning, RBAC, and agent-role-specific database selection to prevent Context Collision, write-lock contention, and Latency Stacking across simultaneous agent executions. The three core namespaces are the Library (global read-only), the Scratchpad (agent-isolated write), and the Episodic Log (sequential audit trail). This architecture is named the Swarm-Sharded Memory Blueprint. Verified production standard as of March 2026.
Q2: How do I prevent Agent Cross-talk in a vector swarm?
Agent Cross-talk where one agent’s unvalidated intermediate output contaminates a peer agent’s retrieval context is prevented through namespace isolation enforced at two levels. At the collection level, each agent writes only to its own Scratchpad collection named scratchpad_{agent_id}_{session_id}. At the metadata level, every vector carries source_agent_id, session_id, and status (provisional or validated) as payload. No agent retrieves from another’s Scratchpad by default. Peer-to-Peer Retrieval is an explicit operation with a status = completed filter never implicit.
Q3: What is Latency Stacking and how is it mitigated?
Latency Stacking is the cumulative delay when multiple agents perform sequential vector retrievals each agent waiting for the previous agent’s retrieval to complete before initiating its own. In a 3-agent sequential chain at 100ms per retrieval, the stack is 300ms of pure vector overhead per loop. Mitigation requires two architectural changes: asynchronous Qdrant upserts so agent writes do not block peer execution, and parallel retrieval via n8n Split In Batches so multiple agents query simultaneously. With both implemented at 20ms retrieval (Qdrant on DigitalOcean 16GB): 20ms total overhead per loop regardless of agent count.
Q4: Can n8n handle multi-agent memory routing?
Yes. n8n handles multi-agent memory routing via three mechanisms. Native Qdrant vector store nodes route Executor outputs to specific named Scratchpad collections based on agent_id extracted from the triggering webhook payload no custom code. Parallel branch execution generates all agent embeddings simultaneously eliminating sequential embedding bottlenecks. Switch nodes route different agent outputs to the correct namespace based on agent_role metadata. The n8n plus Qdrant combination is the verified sovereign orchestration stack for multi-agent memory. Verified March 2026.
Q5: Is shared memory better than isolated memory for agent swarms?
Shared memory is the correct architecture for facts the Library namespace, containing domain knowledge that does not change mid-execution and is safe for all agents to access. Isolated memory is mandatory for reasoning the Scratchpad namespace, containing each agent’s provisional, in-progress outputs that have not yet been validated by the Reviewer. Mixing these two putting provisional reasoning in a shared namespace is the definition of the Context Collision failure mode. Share facts. Isolate reasoning. This is the fundamental rule of swarm memory design.
Q6: What is Consensus Retrieval?
Consensus Retrieval is a pattern where the Reviewer agent queries both the Library namespace and the Executor’s Scratchpad output simultaneously, computes cosine similarity between the results, and flags divergence above a configured threshold as a re-validation requirement. It verifies that the Executor’s output is semantically grounded in validated domain knowledge not in a hallucination or a peer agent’s contaminated intermediate state. Use for high-stakes outputs only: legal clause interpretation, medical recommendations, financial risk calculations, compliance decisions. The dual-query overhead is not warranted for routine tool call validations.
Q7: Should I use Vapi for voice agent swarms?
Yes, with a specific architectural requirement. In a voice swarm built on Vapi or Retell AI, the conversational agent must have a dedicated low-latency episodic store isolated from the shared Library namespace to maintain sub-500ms conversation context retrieval. The voice pipeline latency budget is approximately 800–1,200ms total: speech-to-text, context retrieval, LLM inference, text-to-speech. Vector retrieval cannot consume more than 50ms of that budget. This requires a co-located Qdrant instance with Binary Quantization and a Redis warm cache not a cloud-API vector store with network round-trip overhead. For the full voice agent database architecture see: Retell AI vs Vapi 2026 at ranksquire.com/2026/01/31/retell-ai-vs-vapi-2026/
Q8: Does metadata isolation affect vector search speed?
Minimal overhead when using a database with pre-scan filter architecture. In Qdrant, payload filtering executes as a pre-scan operation before HNSW graph traversal adding approximately 6–9ms to a baseline 20ms query, for a total of 26–29ms. In databases using post-retrieval metadata filtering (scanning the full result set after vector search), the overhead is 100–300ms. At production swarm I/O volumes, the difference between pre-scan and post-scan filtering is the difference between a real-time system and a batch process. Qdrant’s pre-scan architecture is the specific reason it is selected for the Executor Scratchpad role in the Swarm-Sharded Memory Blueprint.
Q9: How does Docker help in multi-agent swarm deployments?
Docker enables each database component Qdrant, Redis, n8n to scale independently of the agent logic layer. Qdrant can add shard containers horizontally without touching n8n or agent code. Redis can be promoted to a cluster configuration without changing Qdrant. Container isolation prevents library version conflicts between Rust-based Qdrant, C-based Redis, and Node.js-based n8n on the same DigitalOcean Droplet. Resource limits per container prevent any single component from consuming full Droplet RAM during an index rebuild event. Total deployment: one docker-compose.yml, 30 minutes on a fresh Droplet.
GLOSSARY: MULTI-AGENT VECTOR DATABASE ARCHITECTURE
11. FROM THE ARCHITECT’S DESK