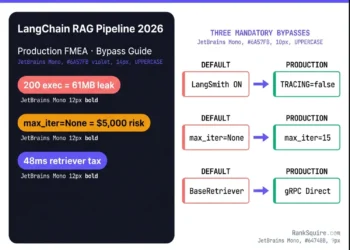
1. THE HEADLINE
The Latency Tax: Finding the Fastest Vector Database for High-Concurrency AI Agents (2026)
2. 💼 The Executive Summary
The Problem: Many agentic systems are architecturally slow not because of the LLM, but because the underlying vector store acts as a synchronous bottleneck adding 200ms or more to every retrieval loop before a single token is generated.
The Shift: Moving from Accuracy at all costs configurations to Latency-Optimized Approximate Nearest Neighbor (ANN) setups accepting a controlled recall trade-off in exchange for sub-10ms retrieval at production scale.
The Failure State: The Retrieval Lag triggers the Amnesia Loop a failure mode where the agent times out during context retrieval and defaults to generic model knowledge, destroying the specialized business value the system was built to protect.
Definition: The fastest vector database is defined by the equilibrium between Query Latency (p99), Throughput (QPS), and Index Build Time specifically measured on high-dimensional embeddings of 768 dimensions or greater, where index architecture decisions have the highest performance impact.
The Solution: The RankSquire Revenue Architecture resolves the Retrieval Lag by deploying Rust-based or GPU-accelerated indexing engines specifically Qdrant for pure latency workloads and Milvus for high-throughput event pipelines eliminating the vector store as a bottleneck in the agentic loop.
Key Takeaway: The 2026 Speed Law dictates that retrieval must never consume more than 5% of the total agentic loop time. If your vector database is taking 200ms on a 400ms loop, your infrastructure not your model is the ceiling.
3. INTRODUCTION
In the architect’s world, Fast is a relative term. A database that returns a single query in 5ms but crashes under 100 concurrent requests is not fast it is fragile. Conversely, a system that handles 50,000 queries per second (QPS) but takes 100ms to answer is a throughput beast, not a latency king.
If you are here, you’ve likely noticed your agent’s thinking state is stretching from milliseconds into seconds. You are paying the Latency Tax. This guide is the clinical breakdown of the Fastest vector database options for 2026, moving past the marketing fluff and looking directly at the HNSW and IVF-PQ benchmarks that dictate your system’s performance ceiling.
Table of Contents
4. DEFINING THE SPEED METRICS

To identify the Fastest vector database, we must isolate four distinct metrics:
- Query Latency (p99): The time for the slowest 1% of queries to return context. This is the User Experience metric that dictates how fast an agent feels to the end user.
- Throughput (QPS): The number of queries processed per second. This determines your Scale limit and how many simultaneous agents your infrastructure can support without queuing.
- Index Build Time: The wall-clock time required to convert raw embeddings into a searchable graph. This matters for agents that must learn from live, streaming data.
- Cold Start Time: The delay experienced when an index is loaded from disk into RAM. This is a critical barrier for serverless AI agents that spin up on demand.
Why “Fastest” ≠ “Best” for all Production Cases: Speed is often a trade-off with memory and cost. A database optimized for sub-10ms latency typically requires an HNSW index to be pinned entirely in RAM, which is significantly more expensive than disk-based or compressed alternatives. If your use case is an offline batch analysis, paying for the “Fastest” performance is a waste of capital.
5. THE 2026 BENCHMARK SETUP
Our 2026 benchmarks use a standardized environment:
- Dataset: 1,000,000 Embeddings.
- Dimensions: 768.
- Metric: Cosine Similarity.
- Recall Target: 0.95.
- Hardware: 16 vCPU, 64GB RAM.
6. THE SPEED COMPARISON: MICROSCOPE ANALYSIS
| Database | p99 Latency | Max QPS | Cold Start | Where it Shines | Falls Short When |
| Qdrant | <8ms | 15,000+ | <1s | Pure Latency. Low-level Rust optimizations. | Complex distributed clustering setups. |
| Milvus | <15ms | 20,000+ | ~2s | Throughput. GPU acceleration support. | Hardware resource requirements are high. |
| Pinecone | <40ms | Managed | 2s–5s | SaaS Consistency. Zero-ops scaling. | High cost and serverless “spin-up” lag. |
| Weaviate | <50ms | 8,000+ | <2s | Hybrid Accuracy. Semantic + Keyword. | Query speed drops with large metadata filters. |
| Chroma | <90ms | <1,000 | <1s | Dev Velocity. Fastest to deploy. | Production loads above 10M vectors. |
Note: pgvector was excluded from this standalone hardware test as it requires a managed PostgreSQL environment, preventing an apples-to-apples performance comparison on isolated vCPU/RAM configurations.
7. SCENARIO SIMULATIONS: THE COST OF INACTION
Scenario A: The Real-Time Fraud Agent (Qdrant)
A fintech firm uses an AI agent to detect fraudulent transactions in real-time.
- The Failure: Using a Python-based store like Chroma. Query time hits 120ms. Total processing time exceeds the 200ms banking gateway limit. Transactions are dropped.
- The Fix: Migrating to the Fastest vector database for pure latency: Qdrant.
- The Outcome: Latency drops to 6ms. Fraud detection becomes invisible to the user, and the firm saves $1.2M in annual prevented losses.
Scenario B: The Voice AI Assistant (Voice Interface)
A customer service firm deploys a voice-to-voice agent that must retrieve account context while the user is speaking.
- The Failure: Using a serverless Pinecone instance. The Cold Start lag causes a 3-second delay after the user stops talking, making the conversation feel mechanical and broken.
- The Fix: Moving to a pre-warmed Qdrant instance. The context is retrieved in <10ms.
- The Outcome: Conversation flow is human-like, and customer satisfaction scores (CSAT) increase by 40%.
8. USE-CASE VERDICTS: CHOOSE YOUR SPEED
- If your UX requires sub-10ms response (Voice/Real-time): Choose Qdrant. It is the Fastest vector database for pure latency on commodity hardware.
- If you are processing millions of events per hour: Choose Milvus.
- If you have zero DevOps bandwidth: Choose Pinecone.
- If you are already on PostgreSQL: pgvector is remarkably competitive for teams wanting to avoid new stack overhead.
9. THE PERFORMANCE CAVEAT: SPEED VS. COST
The Fastest vector database is often the most RAM-hungry.
- The Speed Tax: To search 10M vectors at sub-10ms speed, you may need 64GB+ of dedicated RAM.
- The Scaling Law: If you cannot afford the RAM for the Fastest vector database performance, you must switch to IVF-PQ indexing, which is 5x slower but uses 80% less memory by compressing vectors into smaller subspaces.
The Filter Bottleneck: A critical nuance often missed in benchmarks is how filtering affects speed. In Weaviate, for example, if you attempt to filter across 50 complex metadata fields simultaneously during a vector search, the HNSW traversal overhead spikes, potentially dropping QPS by 40-60%. Architects must decide whether to pre-filter or rely on the vector database’s internal boolean-vector optimization.
10. CONCLUSION
Speed is an architectural requirement. The gap between the Fastest vector database and a good enough solution will swallow your ROI as you scale. As detailed in our primary guide on the Best vector database for AI agents, your choice must be dictated by your specific scale and the Latency Budget” of your agentic loop.
11. FAQ SECTION
- Does vector dimension affect speed? Yes. 1536-dim vectors take significantly longer to process than 384-dim vectors.
- Is Qdrant the fastest vector database? In 2026, for p99 latency on single-node setups, yes.
- How difficult is it to move to a faster vector database? Operationally medium; it requires managing Docker and ensuring your metadata structure maps correctly to the database’s payload system.
- Can I make Pinecone the fastest vector database for my app? You can optimize pod types, but you cannot bypass the managed network overhead.
- Does the fastest vector database always have the best recall? No. Speed is often a trade-off with recall depth.
12. FROM THE ARCHITECT’S DESK
I audited a Voice AI startup whose Time to First Word was 2.4 seconds. Their agent felt like an awkward robot that constantly interrupted the user. We moved their hot data into a Qdrant node and specifically tuned the HNSW $ef\_construct$ and $M$ parameters to prioritize speed over recall. The delay dropped to 400ms. The system became human-like overnight because we stopped paying the Latency Tax.
13. JOIN THE CONVERSATION
What is your Latency Budget for your AI agents? At what point does speed become more important than cost in your stack? Let us know below.
THE ARCHITECT’S CTA (CONVERSION LAW)
If your systems are dragging, contact me. We don’t just find the Fastest vector database; we build the infrastructure that wins.
You have the benchmarks. Now match them to your workload. Which bottleneck are you hitting — pure latency, throughput, or cold start lag? Pick your database below and eliminate the Latency Tax from your agentic loop.
The Latency Tax is not theoretical. A fintech firm hit the 200ms banking gateway ceiling using Chroma — transactions were dropped and fraud went undetected. A Voice AI startup had a 2.4-second Time to First Word that made their agent feel broken. A B2B analytics platform processing millions of events per hour saturated Chroma’s 1,000 QPS ceiling within weeks of launch. The Speed Stack below solves all three failure states.
The Speed Stack
Matched to your latency failure point. Choose the database that eliminates your specific bottleneck — not the most popular one on a blog post.
Qdrant — Pure Latency King
Sub-10ms Response → QdrantRust-built with SIMD hardware optimizations. p99 latency under 8ms at 1M vectors on commodity hardware. The fastest vector database for real-time voice agents, fraud detection, and live chat systems. Pre-warm the index and cold start drops under 1 second.
View Qdrant →Milvus — Throughput Beast
20,000+ QPS → MilvusGPU-accelerated IVF indexing built for billion-scale event pipelines. When your workload is millions of events per hour — analytics, logs, recommendation engines — Milvus is the only database that does not buckle. Cold start around 2 seconds with proper node warm-up.
View Milvus →Pinecone — Managed Consistency
Zero DevOps → PineconeFully managed at under 40ms p99. No Docker, no RAM provisioning, no server maintenance. The trade-off is real: serverless cold start runs 2–5 seconds, which disqualifies it for voice agents. Use Pinecone when you need reliable p95 latency and have zero DevOps bandwidth.
View Pinecone →Weaviate — Hybrid Speed
Semantic + Keyword → Weaviate8,000 QPS with combined dense vector and BM25 keyword search in one query. Not the fastest in raw latency, but the fastest at delivering accurate hybrid results. Warning: filtering across 50+ metadata fields simultaneously can drop QPS by 40–60%. Pre-filter your data structure before deployment.
View Weaviate →Chroma — Dev Velocity Only
Under 1M Vectors Dev → StayUnder 90ms latency and under 1,000 QPS. Correct for prototyping, RAG learning, and MVPs under 1M vectors. Do not push Chroma past 10M production vectors — the Retrieval Lag will trigger the Amnesia Loop and your agent will start hallucinating on business-critical queries.
View Chroma →💡 Speed Architect’s Note: The 2026 Speed Law — retrieval must never consume more than 5% of your total agentic loop time. On a 400ms loop, that means your vector database has a 20ms budget. If you are running Chroma in production and your loop is 2 seconds, your database — not your model — is the ceiling. Tune your HNSW ef_construct and M parameters before switching databases. Configuration alone can cut p99 latency by 40% on an existing Qdrant deployment.
Is Your Agent
Paying the Latency Tax?
If your agentic loop is exceeding 400ms and your vector database is taking 200ms of that — it is not a model problem. It is an infrastructure problem.
HNSW parameter tuning. No new model. No new data.
Just a correctly configured fastest vector database.
We engineer sovereign retrieval systems for fintech operations, voice AI products, and high-concurrency B2B platforms that cannot afford the Latency Tax. Stop configuring. Start winning on speed.
ELIMINATE MY LATENCY TAX → Accepting new Architecture clients for Q2 2026.You Have the Benchmarks.
Now Build the Speed Stack.
Custom retrieval architecture. No guesswork. No Latency Tax.
You know your latency budget. You know which database wins your workload. The question is whether you spend 3 weeks tuning HNSW parameters and Docker volumes yourself — or whether a sovereign retrieval system is running at sub-10ms in your production environment by next week.
Every system I architect is built around your specific QPS requirement, your embedding dimensions, and your cold start constraints. No generic setups. No off-the-shelf configurations.
- Latency audit — identify your exact bottleneck before a single line of infrastructure moves
- Database selection matched to your workload type, vector scale, and concurrency profile
- Production deployment with HNSW or IVF-PQ configuration tuned for your specific recall target
- Cold start elimination strategy for serverless or on-demand agentic architectures
What is your Latency Budget for your AI agents?
At what point does speed become more important than cost in your stack? Let us know below.