Pinecone Pricing 2026 Analysis
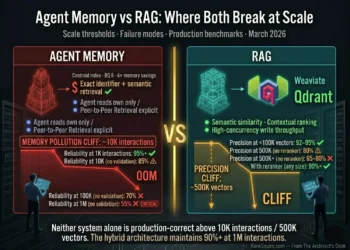
Pinecone pricing 2026 is a four-component billing system write units, read units, storage, and capacity fees, designed for read-heavy RAG workloads. AI agent deployments violate every assumption baked into that model. The result: production bills that run 3–5× above calculator estimates, driven by write unit saturation and capacity fees that activate silently at sustained concurrent agent load.
TL;DR — QUICK SUMMARY
→ Pinecone pricing 2026 has three tiers: Free (1 serverless index, 2GB storage), Serverless (pay-per-use: WU + RU + storage + capacity fees), and Dedicated pods (fixed cost per pod/month).
→ Serverless true cost at 10M vectors with AI agent write load: $99–199/month significantly above the $78/month base estimate because capacity fees activate at sustained concurrent agent load above 500 queries/minute.
→ The free tier gives you 2GB storage and 1 serverless index. It breaks the moment you exceed 2GB, need more than 1 index, or require RBAC for team access.
→ Pods become cheaper than serverless at approximately 10M+ vectors when serverless bills exceed $140/month. Below that, serverless is cheaper unless contractual latency SLAs are required.
→ The “When to Leave Pinecone” threshold: monthly bill above $300 → self-hosted Qdrant on DigitalOcean at $106/month fixed recovers migration cost in 60 days.
KEY TAKEAWAYS
→ Pinecone Serverless is optimized for read-heavy, low-write workloads. AI agents are write-heavy. Every agent loop iteration produces a billable write. The mismatch produces bills 3–5× above calculator estimates at production agent load.
→ Write units are the cost driver, not read units. Each upsert of one 1,536-dim vector with full agent payload costs 3–4 write units. At 1M upserts/day: $42/month in write units alone — before any storage or capacity fees.
→ Capacity fees are the unpredictable component. They activate at sustained concurrent load above an undisclosed threshold and are not surfaced in the base per-unit pricing. Observed in production at $50–150/month for 10-agent deployments.
→ The free tier is development-only. 2GB storage corresponds to approximately 350K uncompressed vectors at 1,536 dimensions. A 10-agent system exhausts this in 67 days at full payload write frequency.
→ Pod-based pricing removes write unit variable cost but introduces a fixed monthly commitment ($70–700/month per pod). Pods are correct when query volume is predictably high, latency SLAs are contractual, and vector count is stable above 20M.
→ The self-hosted crossover: at $300/month Pinecone spend, self-hosted Qdrant on DigitalOcean ($106/month fixed) recovers migration engineering cost within 60 days.
QUICK ANSWER
(Daily Queries × avg RU × $0.00000025 × 30)
(Vector Count × storage rate × 30)
Capacity Fees (variable — activates at sustained concurrent load)
PINECONE PRICING 2026 — HOW THE BILLING MODEL WORKS
EXECUTIVE SUMMARY: THE PINECONE PRICING PROBLEM
Pinecone pricing 2026 is not opaque — the per-unit rates are published. The problem is that the pricing calculator assumes a read-heavy RAG workload: infrequent writes, moderate queries, stable storage. AI agent deployments violate all three assumptions simultaneously. Agents write to memory stores on every loop iteration. They query multiple namespaces per reasoning step. Their vector collections grow continuously as episodic logs accumulate. The calculator produces a number. The production bill is 3–5× that number.
From calculator thinking to production-accurate cost modeling: write frequency at agent loop rate, query volume at concurrent agent count, storage growth at episodic accumulation rate, and capacity fee activation at sustained concurrent load.
An accurate Pinecone billing forecast before the first production vector is written — and a clear decision threshold for when self-hosted infrastructure becomes the financially correct choice.
The Pinecone pricing calculator is accurate for the workload it is designed for. An AI agent is not that workload. Calculate at your actual write frequency and query volume before you commit.
Table of Contents
1. The Pinecone Billing Formula Calculate Before You Commit

Pinecone pricing 2026: The Complete Formula
(Daily Queries × Avg RU per Query × $0.00000025 × 30)
(Total Vectors × Bytes per Vector / 1GB × $3.60 × 30 / 30)
Capacity Fees
Write unit rate (March 2026): $0.0000004 per WU. One base upsert = 1 WU. A 1,536-dim vector with full agent payload = 3–4 WU per upsert.
Example: 1M writes/day × 3.5 WU avg × 30 = $42/month.
Read unit rate: $0.00000025 per RU. One 1,536-dim query = 1–2 RU base. 20K queries/day × 2 RU × 30 = $0.30/month. Read units are not the cost driver.
1,536-dim float32 = 6,144 bytes. 10M vectors uncompressed = ~$221/month. Compressed = ~$7/month. Always enable compression on production indexes.
Activates at sustained concurrent load (10+ agents sustaining >500 queries/min). Observed range: $50–150/month. Most teams do not account for this.
2. Pinecone Serverless Pricing 2026: Real Costs at Three Usage Profiles
What Serverless Means for Billing
Pinecone Serverless scales read and write capacity independently without pre-provisioning. No minimum commit. No reserved capacity charge at low volume. This model is correct for bursty, unpredictable, or prototype workloads. It is expensive for sustained concurrent write loads — which is exactly what AI agents produce.
Usage ProfilesRU cost: $0.075/month
Storage: ~$0.20/month
Capacity fees: $0
RU cost: $0.75/month
Storage: ~$2/month
Capacity fees: $0
RU cost: $0.30/month
Storage: ~$7/month
Capacity fees: $50–150/month
The Pinecone pricing calculator defaults to RAG-profile assumptions. Most teams enter low write frequencies and underestimate production cost by 5–10×. The write frequency field is the single most important input. Enter your actual agent loop write rate — not the default.
Pinecone Serverless indexes cold-start after more than 5–10 minutes of inactivity with 200–800ms latency per index. For 10 agents each triggering a simultaneous cold start: 4,000ms pipeline overhead at activation. Not a billing cost — a compounding latency cost that degrades agent pipeline performance at every burst activation.
3. Pinecone Free Tier 2026: What It Includes and Where It Breaks
What the Free Tier Includes
A 10-agent system at 30MB/day write rate exhausts 2GB storage in 67 days. With minimal metadata at 12MB/day: 167 days. Either way, the free tier is not a long-term option for any agent deployment writing at production frequency.
A production AI agent memory architecture requires at minimum one L2 semantic memory collection, one L3 episodic log collection, and optionally a tool memory registry — three or more indexes. The free tier allows one.
Any multi-engineer team requires role-based access control. The free tier has none. The moment a second engineer touches the deployment, the free tier becomes architecturally unsuitable.
Shared compute provides no uptime or latency guarantee. Any production deployment with user-facing consequences requires a paid tier.
Correct for single-developer prototyping, SDK evaluation, and local testing of embedding and retrieval logic. Not correct for multi-engineer teams, multi-collection architectures, or any deployment with production uptime requirements.
4. Pinecone Pod Pricing 2026: When Pods Beat Serverless
Pod-based Pinecone pricing replaces per-unit billing with a fixed monthly cost per pod.
No WU charges. No RU charges. Fixed cost regardless of write or query volume within pod capacity limits.
Pod Types and Pricing (March 2026)s1.x2: ~$140/month — ~10M vectors
s1.x4: ~$280/month — ~20M vectors
s1.x8: ~$560/month — ~40M vectors
p1.x2: ~$180/month — ~2M vectors
p2.x2: ~$280/month — ~2M vectors
If serverless bill is $99/month: serverless is cheaper than s1.x2. If serverless bill is $199/month: s1.x2 at $140/month is cheaper.
The crossover threshold: when serverless exceeds $140/month at 10M vectors — the s1.x2 pod is the correct choice.
| Configuration | 100K Vectors | 1M Vectors | 10M Vectors |
|---|---|---|---|
| Light Workload (RAG, human-driven queries) | |||
| Storage (compressed) | ~$0.20/mo | ~$2/mo | ~$7/mo |
| Write units (1K–50K writes/day) | ~$0.01/mo | ~$0.24/mo | ~$0.60/mo |
| Read units (5K–200K queries/day) | ~$0.08/mo | ~$0.75/mo | ~$3/mo |
| Capacity fees | $0 | $0 | $0–30/mo |
| Total (light workload) | ~$1–2/mo | ~$3–5/mo | ~$10–40/mo |
| Standard AI Agent Load (10-agent system) | |||
| Storage (compressed) | ~$0.20/mo | ~$2/mo | ~$7/mo |
| Write units (100K–1M writes/day) | ~$1.20/mo | ~$6/mo | ~$42/mo |
| Read units (5K–20K queries/day) | ~$0.08/mo | ~$0.30/mo | ~$0.30/mo |
| Capacity fees | $0 | $0–20/mo | $50–150/mo |
| Total (10-agent system) | ~$2–3/mo | ~$8–28/mo | ~$99–199/mo |
| ⚠ High-Load AI Agent (50-agent system) — $300/mo Trigger Zone | |||
| Storage (compressed) | N/A | ~$2/mo | ~$7/mo |
| Write units (5M writes/day) | N/A | ~$30/mo | ~$210/mo |
| Read units | N/A | ~$1.50/mo | ~$1.50/mo |
| Capacity fees | N/A | $50–100/mo | $100–200/mo |
| Total (50-agent system) | N/A | ~$83–133/mo | ~$318–418/mo ⚠ |
Compression note: Always enable Pinecone’s native compression. Without it, 10M vectors = 61GB = ~$220/mo storage alone.
5. True Cost at Scale: 100K, 1M, and 10M Vectors
Three usage profiles across three scale points
6. Comparison Table: Free vs Serverless vs Dedicated Pods
Pinecone pricing 2026 — all three tiers at AI agent production load
| Feature | Free Tier | Serverless | Dedicated Pods |
|---|---|---|---|
| Monthly cost | $0 | Pay-per-use | From $70/mo fixed |
| Storage limit | 2GB | Unlimited (billed) | Pod-dependent |
| Vector count | ~350K–1.5M | Unlimited (billed) | 5M–40M+ per pod |
| Indexes | 1 index | Unlimited (billed) | Pod-dependent |
| Write unit billing | Included free | $0.0000004/WU | Not applicable |
| Read unit billing | Included free | $0.00000025/RU | Not applicable |
| Cold start penalty | Yes (shared) | Yes (200–800ms) | None — always warm |
| Latency SLA | None | None | Yes — contractual |
| RBAC / team access | None | Yes | Yes |
| Self-host option | None | None | None |
| GDPR / data residency | Shared infra | US-hosted default | Region options |
| True cost (10M, AI agent) | Not applicable | $99–199/month | $140/mo (s1.x2) |
| True cost (1M, RAG) | ~$0 (free) | ~$3–5/month | $90/mo (p1.x1) |
| Migration trigger | 2GB storage | $300/month bill | 20M+ or SLA required |
| Verdict | Dev only | Up to $300/mo | 20M+ or SLA needed |
| Feature / Metric | Free Tier | Serverless | Dedicated Pods |
|---|---|---|---|
| Monthly cost | $0 | Pay-per-use | From $70/mo fixed |
| Storage limit | 2GB | Unlimited (billed) | Pod-dependent |
| Vector capacity | ~350K–1.5M | Unlimited (billed) | 5M–40M+ per pod |
| Write unit billing | ✅ Included | $0.0000004/WU | ❌ Not applicable |
| Read unit billing | ✅ Included | $0.00000025/RU | ❌ Not applicable |
| Cold start penalty | ✅ Yes (shared) | ✅ Yes (200–800ms) | ❌ None — always warm |
| Latency SLA | ❌ None | ❌ None | ✅ Contractual SLA |
| RBAC / team access | ❌ None | ✅ Available | ✅ Available |
| Self-host option | ❌ None | ❌ None | ❌ None |
| GDPR / data residency | ❌ Shared infra | ⚠ US-hosted default | ⚠ Region options |
| True cost · 10M vecs AI agent | Not applicable | $99–199/month | $140/mo (s1.x2) |
| True cost · 1M vecs RAG | ~$0 (free tier) | ~$3–5/month | $90/mo (p1.x1) |
| Migration trigger | 2GB storage | $300/month bill | Self-hosted above 20M |
| Best for | Dev / prototype only | Up to $300/mo bill | 20M+ vecs or SLA needed |
7. What Pinecone Cannot Do And Where It Breaks for AI Agents
Architectural Constraints & Hard Limits
8. When to Leave Pinecone: The Self-Hosted Crossover Threshold
This is the section no Pinecone pricing page includes.
DO Block Storage 100GB: $10/month
Write cost: $0 — no per-unit billing
Read cost: $0
Egress: $0 — DigitalOcean includes 6TB/month outbound transfer
Cold start: $0 — always warm, persistent Docker container
The Crossover Point: When your Pinecone bill exceeds $106/month, you are paying more for managed than self-hosted on equivalent infrastructure.
The Migration Trigger: When your Pinecone bill exceeds $300/month, the one-time engineering cost of migration — one engineer-day — is recovered within 60 days.
| Pinecone $106–200/month | → Saves $0–94/mo | → ROI: 3–12 months — evaluate carefully |
| Pinecone $200–300/month | → Saves $94–194/mo | → ROI: 1–3 months — strong case |
| Pinecone $300/month | → Saves $194/mo | → ROI: 60 days ← Migration Trigger |
| Pinecone $500/month | → Saves $394/mo | → ROI: 30 days |
| Pinecone $1,000/month | → Saves $894/mo | → ROI: ~13 days |
Total migration time: 1 engineer, 1 day.
PRODUCTION ARCHITECTURE RESOURCES
9. Conclusion
Pinecone Pricing 2026: Final Architectural Guidance
Pinecone pricing 2026 is transparent on the pricing page. The per-unit rates are published. The billing formula works exactly as documented. The gap between the calculator estimate and the production bill is not a Pinecone problem — it is a calculation problem. Most teams enter RAG-profile defaults and deploy AI agent workloads. The bill reflects the workload they deployed, not the one they modeled.
10.FAQ: Pinecone Pricing 2026
What is Pinecone pricing in 2026?
Pinecone pricing 2026 operates on three tiers. The free tier provides 1 serverless index, 2GB storage (approximately 350K vectors uncompressed), and 1 project at no cost development and prototyping only. The serverless tier charges per write unit ($0.0000004/WU), per read unit ($0.00000025/RU), and per GB of storage (~$3.60/GB/month), plus variable capacity reservation fees at sustained high concurrent load. The dedicated pod tier charges a fixed monthly cost per pod from ~$70/month for an s1.x1 to $700+/month for large p2 pods with no per-unit billing. True cost at AI agent production load with 10 agents and 10M vectors: $99–199/month on serverless including capacity fees.
What are Pinecone’s free tier limits in 2026?
Pinecone’s free tier in 2026 includes 1 serverless index, 2GB storage (approximately 350K vectors uncompressed or 1.5M with compression), 1 project, shared compute with no latency SLA, and no RBAC for team access control. The free tier breaks when you need more than 1 index, exceed 2GB storage, need role-based access for a team, or require guaranteed uptime. A 10-agent system at full payload write frequency exhausts the 2GB limit in approximately 67 days.
How is Pinecone serverless pricing calculated in 2026?
Pinecone serverless pricing 2026 has four components: write units at $0.0000004/WU (a 1,536-dim vector with full agent payload costs 3–4 WU per upsert), read units at $0.00000025/RU (1–2 RU per query), storage at approximately $3.60/GB/month (10M vectors drop from $221/month to ~$7/month with compression enabled), and capacity fees (variable, not published, observed at $50–150/month for 10-agent concurrent AI deployments). Full formula: (Daily Writes × WU × $0.0000004 × 30) + (Daily Queries × RU × $0.00000025 × 30) + (Vectors × storage rate × 30) + Capacity Fees.
When does Pinecone pod pricing become cheaper than serverless?
Pinecone pod pricing becomes cheaper than serverless when the monthly serverless bill exceeds the fixed pod cost for equivalent vector capacity. For a 10M vector deployment: the s1.x2 pod costs $140/month with no per-unit billing, no cold start penalty, and a contractual latency SLA. If the serverless bill exceeds $140/month at 10M vectors which it does for AI agent write-heavy workloads the s1.x2 pod is cheaper. Pods are additionally correct when query volume is predictable, latency SLAs are contractual, and vector count is stable above 20M.
What is Pinecone’s pricing per million vectors in 2026?
Storage cost per million vectors depends on compression. Uncompressed 1,536-dim float32 vectors: 1M vectors = approximately 6.14GB = approximately $22/month storage. With Pinecone’s native compression at 4–6× reduction: 1M vectors = approximately 1.0–1.5GB = approximately $3.60–5.40/month. At 10M vectors compressed: approximately $7/month. Storage is not the primary cost driver for AI agent deployments write unit consumption at agent loop write frequency is.
At what Pinecone monthly spend should I migrate to self-hosted Qdrant?
The migration trigger is a monthly bill above $300. At that level, self-hosted Qdrant on DigitalOcean ($106/month fixed) saves $194/month. The one-time migration cost one engineer, one day is recovered within 60 days. At $500/month Pinecone spend: recovery in 30 days. At $1,000/month: recovery in approximately 13 days. Self-hosted eliminates write unit costs entirely, eliminates egress fees, eliminates cold start penalties, and provides full data sovereignty and GDPR Article 44 compliance by architecture on EEA infrastructure.
FROM THE ARCHITECT’S DESK
The most common Pinecone pricing mistake I see in 2026 is running the pricing calculator with read-heavy RAG defaults and then deploying an AI agent that writes on every loop.
The calculator is not wrong. It calculates exactly what you ask it to calculate. If you enter 1,000 writes per month and 50,000 reads, it returns a number accurate for that workload. An AI agent at production load is 1,000,000 writes per day and 20,000 reads. The bill is not a surprise it is the correct answer to the wrong calculation.
The second mistake: not accounting for capacity fees. They activate at sustained concurrent agent load, appear as a line item with no clear trigger condition, and have no published rate. The difference between a $78/month estimate and a $199/month bill is almost always capacity fees not write units, not storage.
Run the formula from Section 1 at your actual production write frequency before you commit. If the result exceeds $300/month: self-hosted Qdrant is the correct decision before the first production vector is written, not after month three’s bill arrives.