2026 Production LLM Intelligence Rankings
It’s 3am. Your agent loop fires 10,000 API calls in 4 minutes. A tool call returns a broken schema. Retries cascade. Costs spike. And then your legal team asks one question: “Where exactly did our data go?” Benchmark tables don’t answer that. This ranking does.
Six LLM companies are on the shortlist. Every company that made the list is in active production use on AI agent systems in 2026. Every company that did not make it is excluded for a specific, documented reason.
Data verified April 2026TL;DR — QUICK SUMMARY: 2026 INTELLIGENCE SHORTLIST
A model that tops MMLU benchmarks may produce inconsistent tool-call schemas at high concurrency. A model ranked lower may deliver 99.7% consistent structured output across 100,000 agent calls.
Reliably producing structured tool call schemas at 500 RPM concurrent load is architectural — it shows up in production logs, not benchmark tables.
Agents need windows to hold full reasoning chains and prior tool outputs without degrading instruction following at the tail. These are different quality profiles than document retrieval.
DeepSeek, Llama 4, and Mistral now match GPT-4 class performance while offering economics that approach 1/100th the cost through self-hosting.
For HIPAA and GDPR Article 44, sending data to a proprietary API creates a flow regardless of contract. Self-hosting is the only architecturally correct answer.
Route extraction to cheap models (Gemini Flash); route reasoning to frontier models (Claude Opus). This reduces cost by 60–80% without degrading quality.
April 2026 Quick Answer Protocol
2026 Architectural Definition: LLM Providers
LLM companies are organizations that develop, train, and make available large language models for production use — either through managed API access, enterprise licensing, or open-weight model releases for self-hosting.
In 2026, the category spans closed proprietary API providers (Anthropic, OpenAI, Google), hybrid providers that offer both API and open-weight access (Meta, Mistral), and open-weight-only providers (DeepSeek) that release model weights under permissive licenses.
Both categories are correct for specific deployment profiles.
EXECUTIVE SUMMARY: THE LLM COMPANY DECISION
Most engineering teams evaluating LLM companies in 2026 start with the benchmark leaderboard and end with a vendor whose API behavior under production agent load does not match the characteristics that made it look attractive on the benchmark table.
The benchmark problem is specific: LLM benchmark evaluations measure model quality on a curated test set under ideal conditions single inference, clean inputs, no concurrent load, no tool-use schema validation. Production AI agents run at high concurrency with malformed inputs, ambiguous tool call schemas, incomplete context, and error recovery requirements that benchmark tables do not measure.
From benchmark-first evaluation to production-criteria evaluation: API reliability at agent load, tool-use consistency under concurrent calls, context window quality at the tail (not just the headline number), pricing at your actual token volume, and compliance posture for your data residency requirements.
An LLM company selection that survives contact with production load — delivering consistent agent behavior, predictable costs, and a compliance posture that does not require an emergency architectural review when your legal team asks where the data goes.
Table of Contents

1. The 5 Production Criteria That Benchmark Tables Miss
2026 AI AGENT PRODUCTION FIT: EVALUATION CRITERIA
the percentage of API calls that return a correctly structured response when 50–500 concurrent agent sessions are firing simultaneously.
Why it is not on benchmark tables:benchmarks test single inference in controlled conditions. Production agents create concurrent spike load at irregular intervals — agent loops activating simultaneously, each generating multiple API calls per reasoning step.
What to look for:uptime SLA above 99.9%, documented rate limit behavior (graceful queuing vs hard rejection), and retry-safe idempotency guarantees on API calls.
the model’s ability to produce correctly structured tool-call schemas, interpret tool results, and chain multiple tool calls within a single reasoning step — consistently and at production concurrency.
Why it matters for agents:an AI agent that “supports tool calling” and one that reliably executes a 5-tool reasoning chain at 200 RPM are categorically different. The gap shows up in agent loop failure rates, not benchmark tables.
Best performers in 2026:Claude 4 family (highest consistency under concurrent tool-use load), GPT-5.4 (strongest ecosystem of tool integrations), LangGraph (most explicit tool-use state management when orchestrating open-weight models).
instruction-following accuracy when the agent’s context is near capacity — containing a full system prompt, memory injection block, tool call history, prior reasoning chain, and current user input simultaneously.
Why the headline number misleads:a “1M token context window” that degrades instruction following at 200K tokens is not a 1M token context window for agent use. It is a 200K context window with a headline attached.
What to look for:“needle in a haystack” test performance at 80–100% context fill, not just at 10–20% fill.
total monthly API cost at your production token consumption — input tokens (system prompt + context memory injection), output tokens (reasoning + tool calls responses), and any caching discount applicable.
Why entry-price comparisons mislead:a frontier model at $3/M input tokens and $15/M output tokens processes differently from a smaller model at $0.15/M input and $0.60/M output on the same task. The correct metric is cost per correctly completed agent task — not cost per token.
whether sending data to the model API is architecturally compatible with your regulatory obligations — GDPR Article 44, HIPAA, SOC 2, and any sector-specific requirements.
Why SOC 2 certification is not enough:SOC 2 certification means the vendor has audited their security controls. It does not mean your data never leaves the vendor’s infrastructure, is never used for model training, or meets EEA data residency requirements under GDPR Article 44. For these requirements, only self-hosted open-weight models provide architectural compliance.
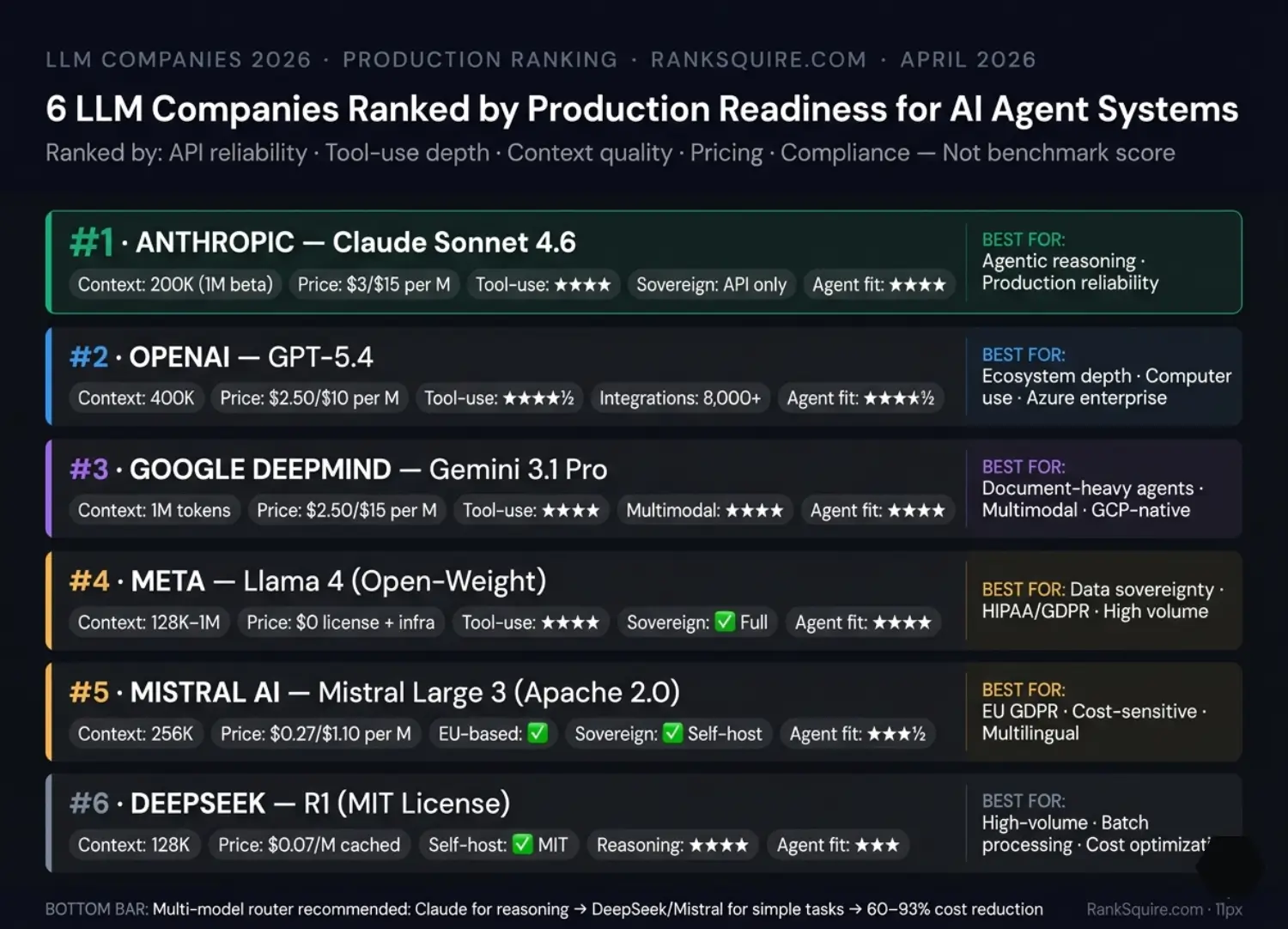
2. The 6 LLM Companies Ranked for AI Agent Systems
2026 PRODUCTION LLM INTELLIGENCE RANKINGS
3. Pricing at Production Scale: What It Actually Costs
April 2026 Production Pricing Analysis
10M input tokens + 2M output tokens per month
(200 sessions/day, 10 agents, 50K input + 10K output tokens per session)
|
Anthropic Claude Sonnet 4.6
10M × $3.00/M (In) + 2M × $15.00/M (Out)
|
$60.00/mo |
|
OpenAI GPT-5.4
10M × $2.50/M (In) + 2M × $10.00/M (Out)
|
$45.00/mo |
|
Google Gemini 3.1 Pro
10M × $2.50/M (In) + 2M × $15.00/M (Out)
|
$55.00/mo |
|
Mistral Large 3 (API)
10M × $0.27/M (In) + 2M × $1.10/M (Out)
← significant cost advantage
|
$4.90/mo |
|
DeepSeek R1 (API, cached)
10M × $0.07/M (In) + 2M × $0.55/M (Out)
← lowest cost option
|
$1.80/mo |
|
Llama 4 / Mistral (Self-Hosted)
License: $0 | Infrastructure: $200–$800/mo
Break-even vs Claude: 3–5 months
|
Fixed HW Cost |
Proprietary APIs (Claude, GPT-5.4) are cost-effective and operationally simpler. The performance advantage justifies the higher per-token cost at this volume.
Mistral API, DeepSeek API, or self-hosted open-weight models. The per-token cost differential becomes the primary budget driver above this threshold. At 50M+ tokens/month: self-hosted is cheaper by 5–10×.
Multi-model router. Route complex reasoning to Claude or GPT-5.4. Route simple extraction and classification to Mistral or DeepSeek. This reduces cost by 60–80% while maintaining frontier model performance where it matters.
4. Open-Weight vs Proprietary: The Sovereignty Decision
Compliance & Sovereignty Architecture 2026
What this means in practice: every prompt, every tool call schema, every agent reasoning step sent to the API passes through the provider’s infrastructure. The provider’s DPA and SOC 2 certification govern what happens to that data — but the data flow itself cannot be eliminated. It is inherent to the API model.
When proprietary APIs are correct:What this means in practice: no data leaves your controlled infrastructure for the LLM inference step. The model weights run on your servers. Your data never reaches an external API. GDPR Article 44 and HIPAA compliance become architectural properties, not vendor contract properties.
When self-hosted open-weight is correct:For RankSquire sovereign stack deployments: Llama 4 or Mistral Large 3 on DigitalOcean GPU Droplet or Hetzner GPU server. The same infrastructure philosophy as self-hosted Qdrant — you own the model, you own the compute, you own the data.
REFERENCE: Best Vector Database for AI Agents 2026 | ranksquire.com/2026/01/07/best-vector-database-ai-agents/5. The Multi-Model Router Pattern
2026 Architectural Standard: Multi-Model Routing
Specs: structured input, predictable output schema, no complex reasoning required
Specs: requires coherent output but not deep reasoning, moderate context window
Specs: multi-step reasoning, tool selection, 64K+ context, reliable tool-call output
6. How to Choose The Decision Framework
LLM SELECTION PROTOCOL: PRODUCTION ARCHITECTURE 2026
→ Data must remain in controlled infrastructure: Llama 4 or Mistral Large 3 self-hosted only.
→ Standard: Mistral or Claude Haiku
→ Complex: Claude Sonnet/Opus or GPT-5.4.
→ 20–50M tokens/month: Mistral API or Router
→ >50M tokens/month: Self-hosted open-weight.
→ DevOps: n8n + Mistral API
→ ML Engineering: Self-hosted Llama 4 / Mistral.
7. Conclusion
Market Summary & Production Framework 2026
The LLM company market in 2026 has never been more capable or more complex. Six companies on this shortlist represent genuine production options for AI agent systems — each with a specific deployment profile where it is the correct choice and specific conditions where it is not.
The benchmark leaderboard is a useful starting point. It is not a production decision framework. Benchmark scores do not tell you tool-call consistency at 500 RPM, context quality at 80% fill, compliance posture under GDPR Article 44, or cost at your production token volume.
The company that survives all four filters is your LLM company.
LLM Architecture Series · RankSquire 2026
The Complete LLM & AI Agent Architecture Library
Every guide needed to select LLM companies, architect agent memory, pair the right vector database, and build production AI systems that reason, remember, and improve.
LLM Companies 2026: Ranked by Production Readiness
Six LLM companies ranked by API reliability, tool-use depth, context quality, pricing at scale, and data compliance — not benchmark scores. The multi-model router saves 93% of LLM API cost.
Agentic AI Architecture 2026: The Complete Production Stack
How LLM companies plug into a production agent stack: orchestration layers, L1/L2/L3 memory, tool-use loops, and sovereign deployment from first principles.
Read → 🧠 Memory AnalysisAgent Memory vs RAG: What Breaks at Scale 2026
The exact failure points that emerge when you pair the wrong LLM with the wrong memory architecture. Where RAG breaks and where persistent vector memory is required.
Read → ⭐ PillarBest Vector Database for AI Agents 2026: Full Ranked Guide
The L2 semantic memory layer that pairs with every LLM on this list. Qdrant vs Weaviate vs Pinecone vs Chroma ranked across 6 criteria for agentic workloads.
Read → 🔧 OrchestrationBest AI Automation Tool 2026: Ranked by Use Case
The orchestration layer that routes tasks between LLM companies. n8n vs Zapier vs Make vs LangGraph — with the multi-model router implementation that cuts LLM cost by 93%.
Read →LLM Architecture 2026: Complete Production System Design
The full transformer architecture, context window mechanics, RAG integration patterns, and production deployment diagrams for every LLM company on this shortlist.
LLM Architecture Series · RankSquire 2026
The Complete LLM & AI Agent Architecture Library
Every guide needed to select LLM companies, architect agent memory, pair the right vector database, and build production AI systems that reason, remember, and improve.
LLM Companies 2026: Ranked by Production Readiness
Six LLM companies ranked by API reliability, tool-use depth, context quality, pricing at scale, and data compliance — not benchmark scores.
Agentic AI Architecture 2026: The Complete Production Stack
How LLM companies plug into a production agent stack: orchestration layers, memory tiers, and sovereign deployment.
Read Guide → 🧠 Memory AnalysisAgent Memory vs RAG: What Breaks at Scale 2026
The exact failure points that emerge when you pair the wrong LLM with the wrong memory architecture.
Read Analysis → ⭐ PillarBest Vector Database for AI Agents 2026: Ranked Guide
The L2 semantic memory layer that pairs with every LLM on this list. Qdrant vs Pinecone vs Weaviate.
Read Guide → 🔧 OrchestrationBest AI Automation Tool 2026: Ranked by Use Case
Orchestration layers that route tasks between LLMs. n8n vs LangGraph — cutting costs by 93%.
Read Guide →LLM Architecture 2026: System Design
Full transformer mechanics, context window engineering, and production deployment diagrams.
8. FAQ: LLM Companies 2026
What are the best LLM companies in 2026?
The six LLM companies with production-ready AI agent capabilities in 2026 are Anthropic (Claude 4 family),
OpenAI (GPT-5.4), Google DeepMind (Gemini 3.1 Pro), Meta (Llama 4 open-weight), Mistral AI (Mistral Large 3,
Apache 2.0), and DeepSeek (R1, MIT licensed). Each serves a specific deployment profile: Anthropic and OpenAI for
agentic reliability, Google for multimodal and long-context, Meta and Mistral for sovereign self-hosted deployment, and DeepSeek for cost-optimized high-volume processing.
Which LLM is best for AI agents in 2026?
Claude Sonnet 4.6 from Anthropic is the top choice for production AI agent systems requiring reliable multi-step
reasoning and consistent tool-use output at concurrent agent load. GPT-5.4 from OpenAI is the strongest alternative
for teams already in the OpenAI ecosystem or requiring native computer use capabilities.
For sovereign deployments where data cannot leave controlled infrastructure Llama 4 (open-weight) or Mistral Large 3 (Apache 2.0) are the architecturally correct choices. The final answer depends on sovereignty requirements, workflow complexity, and production token volume.
How much do LLM APIs cost in 2026?
At 10M input tokens plus 2M output tokens per month, verified April 2026 pricing: Claude Sonnet 4.6 costs
approximately $60/month ($3/M input, $15/M output). GPT-5.4 costs approximately $45/month ($2.50/M input, $10/M output). Gemini 3.1 Pro costs approximately $55/month ($2.50/M input, $15/M output).
Mistral Large 3 via API costs approximately $4.90/month ($0.27/M input, $1.10/M output). DeepSeek R1 via API costs approximately $1.80/month ($0.07/M cached input). Self-hosted open-weight models have zero licensing cost and infrastructure cost of $200–800/month depending on GPU requirements, breaking even with proprietary APIs at approximately 50M+ tokens/month.
What is the difference between open-weight and proprietary LLMs?
Proprietary LLMs (Claude, GPT-5.4, Gemini) are accessed exclusively via managed APIs all data passes through the provider’s infrastructure. Open-weight LLMs (Llama 4, Mistral Large 3, DeepSeek R1) release their model weights under permissive licenses (MIT, Apache 2.0), allowing self-hosted deployment on your own infrastructure where no data leaves your environment.
For GDPR Article 44 compliance, HIPAA regulated data, and high-volume deployments where per-token cost becomes prohibitive, open-weight self-hosted models are the architecturally correct choice. For teams without GPU infrastructure, operational simplicity and faster time-to-production favor proprietary APIs.
What is a multi-model LLM router and should I use one?
A multi-model LLM router is an orchestration layer (typically n8n or a custom Python service) that classifies each AI task by complexity and routes it to the most cost-effective model that can complete it reliably. Simple tasks like classification and extraction route to cheap models (DeepSeek at $0.07/M, Gemini Flash at $0.15/M).
Complex agentic reasoning routes to frontier models (Claude Sonnet at $3/M). A correctly implemented router reduces LLM API costs by 60–93% versus sending all tasks to a single frontier model. At 10M tokens/month this saves $55/month. At 100M tokens/month it saves $550+/month. The implementation cost one n8n workflow with a classification step is recovered within days at medium production volume.
Which LLM company is best for GDPR compliance?
For strict GDPR Article 44 compliance requiring data residency within the EEA with no data transfers to non-EEA infrastructure, Mistral AI is the correct proprietary API choice the company is EU-based (Paris) and EU infrastructure is the default. Mistral Large 3 is also Apache 2.0 licensed, enabling self-hosted deployment on DigitalOcean Frankfurt or Amsterdam for complete architectural GDPR compliance.
Llama 4 (Meta, open-weight) self-hosted on EU infrastructure is equally compliant by architecture. All proprietary API providers offer GDPR Data Processing Agreements and cloud region selection, but data flows to external infrastructure regardless of the DPA making self-hosted open-weight the architecturally cleanest solution for regulated data.
9. FROM THE ARCHITECT’S DESK
Architectural Inquiry: The 2026 Engineering Standard
Both take less time than explaining to your legal team why the production data ended up in a jurisdiction your compliance framework does not allow.
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.
Related Stories

How to Choose an AI Automation Agency in 2026 (5 Tests That Actually Work)
AI AUTOMATION AGENCIES 2026: THE 5-POINT EVALUATION FRAMEWORK AI automation agencies in 2026 range from genuine agentic AI builders deploying sovereign n8n stacks and LLM-powered tool-use loops —...
Pinecone Pricing 2026: True Cost, Free Tier Limits and Pod Crossover
Pinecone Pricing 2026 Analysis Cost Saturation Warning Pinecone pricing 2026 is a four-component billing system write units, read units, storage, and capacity fees, designed for read-heavy RAG workloads....
Agent Memory vs RAG: What Breaks at Scale 2026 (Analyzed)
Agent Memory vs RAG — The Scale Threshold Analysis L12 Retention: All 3 triggers present Asking what breaks at scale is the wrong question to ask after you...

Vector DB Cost Traps in AI Agents: $300/Month Trigger (2026)
📅Last Updated: March 2026 💸Cost Model: Production AI Agent Load · Write + Read + Egress Included 🗃️Configs Compared: Pinecone Serverless · Dedicated · Qdrant Cloud · Qdrant...