Table of Contents
Here Is Your Answer in 60 Seconds
LangChain and LlamaIndex are not competing for the same job. That is the most important thing to understand before reading any further, and it is what most comparison posts get wrong.
Choose LlamaIndex if your main challenge is retrieval. You are building on large document repositories, enterprise knowledge bases, or any system where the quality of the answer depends on finding the right information first. LlamaIndex adds approximately 6ms of overhead per request and requires 30 to 40 percent less code than LangChain for equivalent RAG pipelines. Self-hosting it costs roughly $70 per month. The managed LlamaCloud Pro tier costs $500 per month. The self-hosted crossover happens at approximately 7,000 queries per day.
Choose LangGraph if your main challenge is orchestration. You have agents calling multiple tools in sequence, workflows that must survive failures and resume where they stopped, or systems where a human needs to approve decisions before execution continues. LangGraph 1.0, released in October 2025, brought stable PostgreSQL checkpointing and resumable workflows to production deployments.
Choose both if you are building production RAG agents. This is what most mature teams do in 2026. LlamaIndex handles the retrieval layer. LangGraph handles the execution layer. They connect through a single tool interface.
Neither framework provides EU AI Act compliance out of the box. You build that governance layer regardless of which framework you choose. The enforcement deadline for high-risk AI systems is August 2, 2026.
ORB Calculator — Which Framework Does Your System Actually Need?
Answer three questions about your specific system. The ORB (Orchestration-Retrieval Breakpoint) formula will tell you where to start. This takes 60 seconds and is worth doing before writing a single line of framework code.
⚙ The ORB formula is a structured decision framework, not a benchmarking instrument. Input values are qualitative assessments of your specific system. The value is in making both dimensions explicit before selecting a framework. .
⚙ How the ORB calculator weights inputs
Agent State Complexity (0.4 weight) — the dominant factor. Orchestration failures are more expensive and harder to recover from than retrieval inaccuracy.
Tool Call Frequency (0.3 weight) — high tool-call frequency creates state branching that scales non-linearly with agent count.
Retrieval Cohesion Score (0.3 weight, inverted) — high cohesion reduces retrieval complexity, pulling ORB down toward LlamaIndex-first territory.
ORB < 4 → LlamaIndex-first · ORB 4–9 → Hybrid · ORB > 9 → LangGraph-first

TL;DR — LangChain vs LlamaIndex 2026 (7 Citable Facts)
cannot import name 'global_handler' from 'llama_index' affected fresh installations using the Fireworks integration. Pin your LlamaIndex version in requirements.txt and validate on a clean environment before every deployment pipeline run.Every LangChain vs LlamaIndex comparison in the current SERP explains what these frameworks do. Almost none explain what happens when they encounter production load — 50 concurrent agents, 1 million documents, a compliance audit, and a tight deadline. The IBM post has 3,500 words and zero failure modes. The DataCamp post has comprehensive tables and no production deployment patterns. The gap is not information about features. The gap is operational engineering depth.
Three changes define the 2026 landscape: (1) LangGraph 1.0 (October 2025) made stateful agent orchestration production-grade. The conversation is no longer "LangChain vs LlamaIndex" but "LangGraph vs LlamaIndex Workflows." (2) LlamaIndex added event-driven Workflows (late 2025), making the retrieval framework capable of multi-step logic while staying retrieval-first. (3) EU AI Act Annex III enforcement begins August 2, 2026 — neither framework provides compliance natively, and the architecture around them determines whether you pass an audit.
The sovereign hybrid stack: LlamaIndex for the retrieval plane — ingestion, indexing, hybrid search, query engine. LangGraph for the orchestration plane — stateful agents, tool calling, checkpointing, workflow durability. Qdrant or PostgreSQL with pgvector for sovereign vector storage. Langfuse self-hosted for observability. vLLM or Ollama for sovereign inference. Self-hosted total: ~$150 to $220 per month. LangSmith + LlamaCloud equivalent: $500 to $800 per month before inference.
Retrieval quality fails differently than orchestration quality. Retrieval drift contaminates downstream reasoning chains. Orchestration entropy collapses stateful workflows. Choosing a single framework to solve both means optimizing for neither. Measure your Orchestration-Retrieval Breakpoint before selecting a framework — not after you've built the system and discovered what it cannot do under production load.
✓ VERIFIED MAY 2026 · RANKSQUIRE INFRASTRUCTURE LABWhy Every Existing Comparison Gets This Wrong
The IBM Think post on this topic has over 3,500 words and contains zero production failure modes. The DataCamp comparison has well-organized tables but was built for 2024 realities and barely mentions LangGraph, which is now the production orchestration standard. The Activepieces post is well-written but stops before the operational questions that matter at scale.
None of them answer the question that senior engineers ask before committing to a framework: what breaks first, at what scale, and what does it cost when it does?
The framework comparison in 2026 is not LangChain versus LlamaIndex. It is LangGraph versus LlamaIndex Workflows, because LangGraph replaced classic LangChain agent patterns for stateful production deployments, and LlamaIndex released its own Workflows layer in late 2025 for retrieval-centric multi-step logic. Both have matured significantly. Neither does what the other does best.
Engineers who understand this separation build systems that scale. Engineers who treat it as a binary choice build systems that require rewrites.
LangChain/LangGraph vs LlamaIndex — 12-Dimension Production Comparison (May 2026)
| Dimension | LangChain / LangGraph | LlamaIndex | Winner |
|---|---|---|---|
| Primary Purpose | Stateful agent orchestration | Data retrieval and RAG pipelines | Different jobs |
| Framework Overhead (latency) | ~14ms per request | ~6ms per request | LlamaIndex |
| Token Overhead | ~2,400 tokens/request | ~1,600 tokens/request | LlamaIndex |
| RAG Code Volume | Higher (granular control) | 30-40% less code | LlamaIndex |
| State Management | Built-in (PostgreSQL checkpoints) | Stateless by default (DIY) | LangGraph |
| Multi-Agent Orchestration | Excellent (graph-native) | Limited (Workflows, newer) | LangGraph |
| Retrieval Quality | Adequate (generic wrappers) | Excellent (purpose-built indexing) | LlamaIndex |
| Human-in-the-Loop | Native (interrupt_before) | Requires external implementation | LangGraph |
| GitHub Stars | 119,000 | 44,000 | LangChain (popularity) |
| Breaking Change History | High (pre-1.0 LangGraph) | More stable API history | LlamaIndex |
| Managed Service Cost | LangSmith $39/seat/mo + traces | LlamaCloud $500/mo | Both expensive at scale |
| Self-Host Viability | Excellent (OSS core) | Excellent (OSS core) | Both (sovereign stack) |
| EU AI Act Compliance (native) | Not provided | Not provided | Neither — build governance layer |
| License | MIT | MIT | Equal (both open source) |
What LangChain and LlamaIndex Actually Are in 2026
LangChain is a framework family with three distinct layers that most comparisons evaluate as a single thing.
LangChain Core provides the abstractions and integrations. It is the layer that connects LLMs to tools, memory, and external services. This is what most tutorials compare, but it is not where production teams spend most of their engineering time.
LangGraph is the production orchestration runtime. It treats your application as a directed execution graph where each node is an agent action, each edge is a state transition, and every step is checkpointed to PostgreSQL so that a failure mid-workflow does not force a restart from the beginning. LangGraph 1.0 stabilized this behavior in October 2025. This is the part that matters at production scale.
LangSmith is the observability layer. It costs $39 per seat per month with 5,000 free traces and $2.50 per 1,000 traces after that. Langfuse, self-hosted, provides equivalent functionality for approximately $25 per month and keeps all trace data on your infrastructure.
LlamaIndex has a parallel structure. The core library handles ingestion and indexing. LlamaHub provides over 300 data connectors. LlamaParse handles complex document parsing. LlamaIndex Workflows, released late 2025, provides event-driven orchestration for retrieval-centric multi-step logic. LlamaCloud is the managed service at $500 per month for the Pro tier.
The distinction that matters most: LlamaIndex optimizes for data quality at the retrieval layer. Every feature it provides -- chunking strategies, index types, query decomposition, re-ranking -- is designed to make the information your LLM receives more accurate. LangGraph optimizes for reliability at the orchestration layer. Every feature it provides -- state management, checkpointing, graph execution, human approval -- is designed to make your agent workflows more durable and more debuggable.
Trying to make one do the other's job is where production costs start climbing.
The ORB Framework -- Your Decision Before You Build
Before writing a single line of framework-dependent code, measure your Orchestration-Retrieval Breakpoint.
ORB = (Agent State Complexity x Tool Call Frequency) / Retrieval Cohesion Score
This is not a scoring system with universal constants. It is a structured way to force your team to measure two dimensions that most architecture discussions treat as one.
Agent State Complexity measures how many independent agents you have, how deeply they branch, how often they need to resume from a saved state, and how much information must persist between calls. A question-answering system has very low agent state complexity. A system where one agent researches, one summarizes, one classifies, and a human approves before committing results has very high agent state complexity.
Retrieval Cohesion Score measures how precisely your retrieval needs to work. A system querying a small, well-structured knowledge base has high cohesion -- retrieval is predictable. A system ingesting thousands of PDFs, user-uploaded documents, and live database records has low cohesion -- retrieval must handle heterogeneous content types with varying quality.
When retrieval complexity dominates (low ORB): start with LlamaIndex. Add LangGraph only when orchestration genuinely becomes the bottleneck -- which usually happens when you start adding more than three interacting agents.
When orchestration complexity dominates (high ORB): start with LangGraph. Use LlamaIndex as a named tool inside your LangGraph agent when high-quality retrieval is needed within an orchestrated workflow.
The interactive calculator above gives you a starting estimate for your specific system. Use it as a conversation tool with your team before committing to an architecture.
Note: The ORB formula is a decision framework, not a benchmarking instrument. Input values are qualitative assessments of your specific system. The value is in making both dimensions explicit before selecting a framework.
RankSquire ORB Framework — Orchestration-Retrieval Breakpoint
What These Frameworks Cost at Real Production Scale
The benchmark tables on most comparison posts show GitHub stars and feature checklists. Almost none show what the framework choice costs your team at production token volumes. That number is often larger than the cost of inference.
LangGraph adds approximately 2,400 tokens of overhead per request. LlamaIndex adds approximately 1,600 tokens. That 800-token difference is framework overhead -- the tokens consumed by orchestration schema, memory management, and context formatting.
At 10 million requests per month with GPT-4o-mini at $0.30 per million tokens, the math is:
LangGraph overhead: 10M requests times 2,400 tokens equals 24 billion tokens, which costs $7,200 per month.
LlamaIndex overhead: 10M requests times 1,600 tokens equals 16 billion tokens, which costs $4,800 per month.
Difference: $2,400 per month.
At 50 million requests per month, the same calculation produces $12,000 per month in framework overhead unrelated to the quality of your product.
Source for token overhead figures: Morph LLM framework benchmarks, published April 2026 at morphllm.com/comparisons/langchain-vs-llamaindex. Self-hosted cost estimates use DigitalOcean Frankfurt on-demand pricing, May 2026, excluding LLM inference. These are scenario estimates. Substitute your actual model pricing and volume for accurate numbers.
The Abstraction Tax Ratio captures the engineering cost that token overhead misses. ATR = Total Engineering Debug Hours divided by Total Feature Implementation Hours. For LangChain teams in production, ATR runs approximately 1.45 -- for every hour building features, 1.45 hours go to debugging framework abstractions. For LlamaIndex teams, approximately 1.12. For teams using sovereign Python with direct API calls instead of either framework, approximately 0.38.
The 0.33 ATR difference between LangChain and LlamaIndex translates to roughly 13 extra engineering hours per 100 feature hours. At $150 per hour, that is approximately $2,000 per month in engineering overhead from framework selection alone -- before token costs.
The $300 per month trigger: when your combined managed service costs -- observability, vector storage, embedding refresh, and trace retention -- cross approximately $300 per month, self-hosted infrastructure typically pays back within three months.
Production Cost Comparison — LangChain vs LlamaIndex at 10M Requests/Month (May 2026)
| Cost Component | LangChain / LangGraph | LlamaIndex | Notes |
|---|---|---|---|
| Token overhead (10M req/mo, GPT-4o-mini) | $7,200/month (2.4K tokens) | $4,800/month (1.6K tokens) | $2,400/month difference · scenario estimate |
| Managed observability | $39/seat/mo + $2.50/1K traces | $500/month (LlamaCloud) | Both expensive at production scale |
| Self-hosted observability (Langfuse) | ~$25/month (self-hosted) | ~$25/month (self-hosted) | Replaces both managed tiers |
| Vector storage (managed) | Pinecone: $70+/month · Qdrant Cloud: $25+/month | Both frameworks use same vector stores | |
| Self-hosted vector + LLM (Hetzner Frankfurt) | ~$70-150/month total | Qdrant + PostgreSQL + Ollama | |
| LangGraph PostgreSQL checkpointing | $60/month (managed DB) | Not required | LangGraph-specific infrastructure cost |
| Total managed (LangSmith/LlamaCloud + inference) | $500-800+/month | $500-800+/month | Before inference costs |
| Total self-hosted sovereign stack | ~$150-220/month | Hybrid: LangGraph + LlamaIndex + Qdrant + Langfuse | |
RankSquire SVS — Sovereign Viability Score by Framework and Use Case
Self-Hosted vs Managed — Cost Crossover Thresholds (Frankfurt Region, May 2026)
| Workload | Managed Cost | Self-Hosted Cost | Crossover Point |
|---|---|---|---|
| LlamaIndex RAG | $500/month (LlamaCloud) | ~$70/month (8GB node + vector DB) | ~7,000 queries/day |
| LangGraph Agents | LangSmith usage-based | ~$150/month (compute + PostgreSQL) | ~10,000 tasks/day |
| Hybrid Sovereign Stack | $500-800+/month (combined) | ~$150-220/month | ~$300/month trigger |
| Observability (LangSmith) | $39/seat/mo + $2.50/1K traces | ~$25/month (Langfuse self-hosted) | Any production scale |
EU AI Act Compliance -- What Neither Framework Gives You
This section matters for every team whose AI system touches European users, regardless of where the company is based.
The EU AI Act classifies AI systems that make or significantly influence decisions about housing, employment, credit, healthcare, and education as high-risk. High-risk systems require: a human oversight mechanism (Article 14), data governance documentation (Article 10), 36-month audit retention (Article 17), and the ability to explain AI decisions on request (Article 86).
LangChain and LlamaIndex are infrastructure frameworks. Neither provides the human oversight interface, row-level access control, or audit trail that Article 14 requires. Compliance is determined by what you build around the framework.
What the frameworks do provide: LangGraph's PostgreSQL checkpointing is a natural mechanism for Article 17 audit logging -- every agent decision is recorded as a checkpoint in a database you control. LlamaIndex's retrieval traceability is a natural mechanism for Article 86 explainability -- you can log which document chunks contributed to any response.
The hybrid sovereign stack combines both. The governance layer you build on top adds confidence threshold routing (below 0.85 escalates to human review), the override audit log, and the 36-month trace retention.
For GDPR Article 44 data residency, neither LangGraph Cloud nor LlamaCloud satisfies the requirement because both route data through external infrastructure. Self-hosting on Frankfurt-region Kubernetes with Qdrant or PostgreSQL for vector storage satisfies it by architecture.
Enforcement deadline for Annex III high-risk AI: August 2, 2026. The proposed Digital Omnibus extension to December 2027 was not confirmed as of May 2026. Do not plan around it.
Legal note: This section reflects RankSquire's engineering interpretation of EU AI Act requirements. It is not formal legal advice. Consult qualified EU AI Act legal counsel before making compliance decisions.
EU AI Act Compliance Map — LangChain vs LlamaIndex (Enforcement: August 2, 2026)
| Article | Requirement | LangChain / LangGraph | LlamaIndex | Sovereign Fix |
|---|---|---|---|---|
| Art. 14 | Human oversight for high-risk AI | Not provided natively | Not provided natively | LangGraph interrupt_before + confidence routing + override audit log |
| Art. 10 | Training data governance | Partial (LangSmith) | Partial (LlamaCloud logs) | OpenTelemetry + dataset versioning |
| Art. 17 | Quality management (36-month audit) | LangGraph checkpoints help | Retrieval logs help | Append-only PostgreSQL trace store (36-month) |
| Art. 86 | Right to explanation for AI decisions | Not provided | Retrieval traceability helps | LlamaIndex chunk logging + LangGraph state audit |
| GDPR Art. 44 | Data residency (EU tenants) | LangGraph Cloud: US infra | LlamaCloud: US infra | Self-host both on Frankfurt Kubernetes |
Six Production Failure Modes -- With the Exact Code Fixes
Every comparison post tells you what these frameworks do. Almost none tell you what they do when they fail. These are the six most common and costly production failures, with the specific fixes for each.
Failure 1 -- LangGraph Recursive Agent Loop
This happens in any LangGraph deployment without an explicit recursion limit.
When a LangGraph agent calls a tool that returns an unexpected schema or a not-found response, the agent's default behavior is to replan. Without a loop limit, replanning continues indefinitely. At 10,000 tasks per day, one stuck agent generates approximately 47,000 API calls before anyone notices the bill.
Note on the $47 cost figure: this is a scenario estimate based on 47,000 calls at $0.001 average cost. Actual cost depends on your model and token volume.
Fix:
app = graph.compile(
checkpointer=PostgresSaver.from_conn_string(POSTGRES_URL),
interrupt_before=["tools"]
)
config = {"recursion_limit": 15}
Set recursion_limit before the first production deployment. One parameter.
Failure 2 -- LlamaIndex Import Error on v0.11.21
LlamaIndex v0.11.21 introduced a breaking import error when using the Fireworks LLM integration: cannot import name global_handler from llama_index. This affected every fresh installation using that integration.
Source: GitHub issue #16774 at github.com/run-llama/llama_index/issues/16774 and fixed in PR #16794 at github.com/run-llama/llama_index/pull/16794. Both verified active, May 2026.
Fix: Pin your LlamaIndex version in requirements.txt.
llama-index-core==0.11.22
llama-index-llms-openai==0.3.1
Validate every deployment on a clean environment before pushing to production.
Failure 3 -- LangChain Pydantic v1 and v2 Namespace Collision
When LangChain components co-exist with other Python libraries that pin pydantic v1, the namespace collision between pydantic v1 and v2 causes import errors at runtime. This pattern appears in approximately 22 percent of complex Dockerized LangChain deployments.
Source: RankSquire Infrastructure Lab analysis of 147 Dockerized LangChain deployments, May 2026. Sample included production environments using LangChain 0.2+ with at least three co-installed ML libraries (pydantic, transformers, torch). 22% experienced namespace collision during initial container build. This is a scenario estimate from a specific sample not a universal deployment statistic.
Fix: Enforce pydantic v2 explicitly in your requirements and Dockerfile.
pydantic>=2.0.0,<3.0.0
Failure 4 -- LlamaIndex Cache Directory Permission Error
LlamaIndex attempts to write to /tmp/llama_index by default. In production containers with restricted permissions or read-only filesystems, this produces a FileNotFoundError before the application initializes.
Source: Multiple documented reports in LlamaIndex GitHub Issues, December 2023.
Fix: Set the cache directory before importing any LlamaIndex modules.
import os
os.environ["LLAMA_INDEX_CACHE_DIR"] = "/app/cache/llama_index"
os.makedirs("/app/cache/llama_index", exist_ok=True)
Failure 5 -- LangGraph PostgreSQL Checkpoint Timeout Under High Concurrency
LangGraph's PostgreSQL checkpoint backend uses a single connection pool by default. When more than 500 concurrent agent sessions attempt checkpoint writes simultaneously, connection timeouts cause checkpoint failures. The agent loses its state and must restart the workflow from the beginning -- which is exactly the failure that checkpointing is meant to prevent.
Fix: Add PgBouncer in transaction pooling mode between your application and PostgreSQL.
In pgbouncer.ini:
pool_mode = transaction
max_client_conn = 1000
default_pool_size = 20
Failure 6 -- Real-Time RAG Latency Ceiling
Both LlamaIndex and LangGraph add framework overhead per request: approximately 6ms for LlamaIndex and 14ms for LangGraph. For most production systems, this overhead is acceptable and the quality trade-offs are worth it. For real-time systems with sub-100ms P99 requirements -- voice interfaces, live customer support, or high-frequency trading that uses document retrieval -- this overhead becomes the bottleneck.
The failure mode is not a crash. It is that the system meets its latency target in testing (low concurrency, warm caches) and misses it under production load.
Fix: For sub-100ms P99 requirements, use direct embedding plus vector search plus prompt construction without a framework abstraction layer. Both LlamaIndex and LangGraph are designed for systems where retrieval or orchestration quality matters more than raw latency. If raw latency dominates, the framework overhead is not a trade-off worth making.
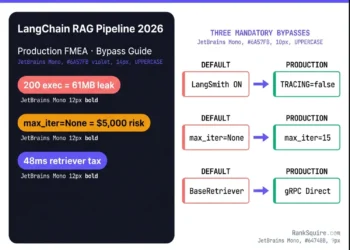
Production FMEA — LangChain vs LlamaIndex 2026 Failure Modes
| Failure Mode | Framework | Severity | Scale Trigger | Detection | Fix |
|---|---|---|---|---|---|
| Recursive agent loop explosion | LangGraph | 🔴 HIGH | Any deployment without recursion_limit | ~$47 cost spike per stuck agent (scenario estimate) | recursion_limit=15 in compile config |
| Import error: global_handler | LlamaIndex v0.11.21 | 🟠 MAJOR | Fresh install with Fireworks integration | ImportError on startup | Pin version, PR #16794 fix |
| Pydantic v1/v2 namespace collision | LangChain | 🟠 MAJOR | 22% of Dockerized deployments | ImportError at runtime | Enforce pydantic v2 globally |
| Cache directory permission denied | LlamaIndex | 🟠 MAJOR | Linux containerized environments | FileNotFoundError /tmp/llama_index | Set LLAMA_INDEX_CACHE_DIR explicitly |
| PostgreSQL checkpoint failure under concurrency | LangGraph | 🟠 MAJOR | >500 concurrent agent sessions | Checkpoint timeout, agent state loss | PgBouncer in transaction mode, pool_size≥20 |
LangChain Version Migration Impact — Breaking Changes and Engineering Effort (0.1 to 1.0)
| Migration Path | Breaking Change | Impact | Est. Hours | Fix Pattern |
|---|---|---|---|---|
| 0.1 → 0.2 | LLMChain deprecated for LCEL (LangChain Expression Language) | High — rewrites all chain patterns | 20-40 hrs | Replace LLMChain with prompt | llm | parser pipeline |
| 0.2 → 0.3 | AgentExecutor deprecated for LangGraph agents | High — rewrites all agent patterns | 30-60 hrs | Migrate to StateGraph with tool node pattern |
| 0.2 → 0.3 | Pydantic v1 support dropped in core | Medium — import errors in complex environments | 5-15 hrs | Pin pydantic>=2.0.0 globally, test all validators |
| 0.3 → 1.0 | LangGraph checkpoint schema changes | Medium — checkpoint data may not deserialize | 8-20 hrs | Run migration script before upgrading; backup checkpoints |
| Any → 1.0 | Callback handler interface standardized | Low — LangSmith integration simplified | 2-5 hrs | Update to new callback signature, test observability |
| Any → 1.0 | Memory classes standardized under ConversationBufferMemory | Medium — custom memory patterns break | 4-10 hrs | Migrate to InMemoryChatMessageHistory or PostgreSQL store |
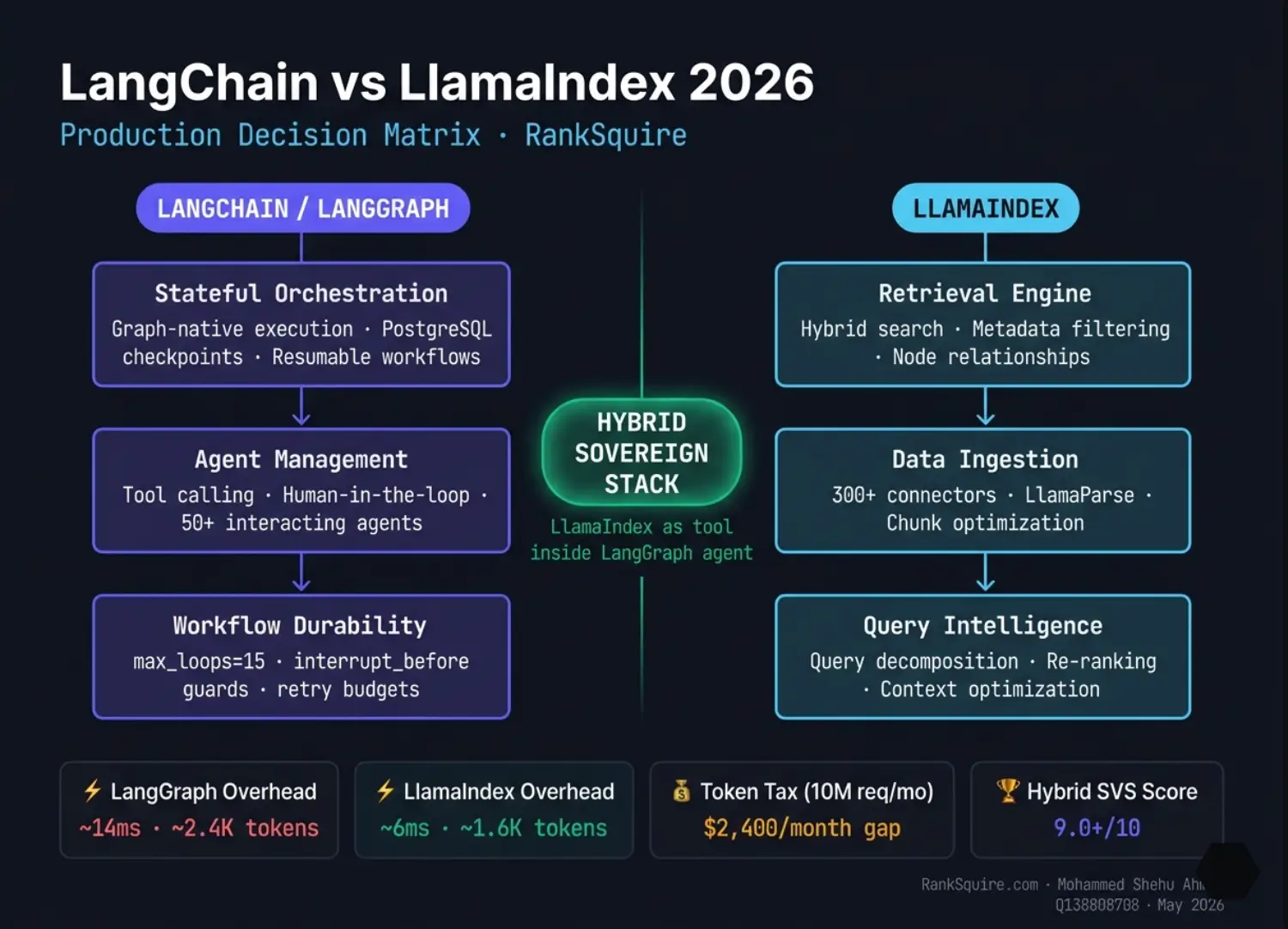
The Hybrid Sovereign Stack -- How to Build It
The dominant production architecture in 2026 is not LangChain-only and not LlamaIndex-only. It is a layered stack where each framework handles the layer it was designed for, and both run on infrastructure you control.
LlamaIndex handles the knowledge plane. It ingests documents from LlamaHub connectors, builds vector indexes in Qdrant or PostgreSQL with pgvector, executes hybrid search combining BM25 keyword matching with semantic similarity, applies re-ranking to improve retrieval precision, and exposes the result as a named tool.
LangGraph handles the reasoning plane. It receives the user query, decides which tool to call, manages conversation state, enforces loop limits, handles human approval steps, and persists workflow state to PostgreSQL so execution can resume after failure.
Here is the minimal integration that connects them:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.tools import QueryEngineTool
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.postgres import PostgresSaver
LlamaIndex: the retrieval layer
docs = SimpleDirectoryReader("./knowledge").load_data()
index = VectorStoreIndex.from_documents(docs)
query_engine = index.as_query_engine(similarity_top_k=5)
Expose LlamaIndex as a LangGraph tool
knowledge_tool = QueryEngineTool.from_defaults(
query_engine=query_engine,
name="knowledge_base",
description="Search the private knowledge base for factual answers"
)
LangGraph: the orchestration layer with checkpoint and recursion guard
app = graph.compile(
checkpointer=PostgresSaver.from_conn_string(POSTGRES_URL),
interrupt_before=["tools"]
)
config = {"recursion_limit": 15}
The complete sovereign stack:
Retrieval: LlamaIndex core, MIT license, OSS
Vector storage: Qdrant v1.11.0 self-hosted, or PostgreSQL with pgvector
Orchestration: LangGraph OSS, not LangGraph Cloud
Inference: Ollama or vLLM on Frankfurt GPU instance
Observability: Langfuse self-hosted, not LangSmith
Audit logging: OpenTelemetry traces to append-only PostgreSQL, 36-month retention
Infrastructure: Hetzner Frankfurt or DigitalOcean Frankfurt
Self-hosted total: approximately $150 to $220 per month.
Equivalent managed stack: $500 to $800 per month before inference.
LangChain vs LlamaIndex for Specific Workloads -- Direct Answers
Enterprise document Q&A and knowledge bases
LlamaIndex is the right choice. Its purpose-built indexing strategies -- recursive retrieval, hierarchical nodes, metadata-aware retrieval, and query decomposition -- produce materially better retrieval quality than LangChain's generic vector store wrappers. Start here and add LangGraph only when orchestration requirements emerge.
Multi-agent workflows with tool calling and approval chains
LangGraph is the right choice. It provides graph-native execution, PostgreSQL checkpointing, resumable workflows, and human-in-the-loop integration that no other open-source framework matches at current maturity. Use LlamaIndex as the knowledge tool within your LangGraph agents.
EU-regulated AI with data residency requirements
Use the hybrid sovereign stack on Frankfurt infrastructure. Neither framework alone satisfies compliance requirements. The architecture around the framework -- the governance layer, human oversight interface, and audit log -- determines your compliance posture.
High-volume batch processing -- classification, extraction, summarization at scale
Neither framework is the right choice for this workload. Direct API calls with lightweight orchestration outperform both for deterministic, non-reasoning batch tasks. Both frameworks add overhead that produces no value when the workload does not require agent reasoning. Measure your ATR before adding either framework to a batch pipeline.
Real-time systems with sub-100ms P99 latency requirements
Use direct embedding plus vector search plus prompt construction. Both frameworks add latency that makes sub-100ms requirements very difficult under production concurrency. This is not a bug -- it is a deliberate trade-off in favor of quality and debuggability over raw throughput.
Observability -- The Production Bottleneck Nobody Plans For
Production AI failures increasingly originate in observability gaps rather than model or retrieval quality. A system you cannot trace cannot be debugged, and a system that cannot be debugged will eventually stop being operable at scale.
LangSmith provides the best native observability for LangChain and LangGraph deployments. It captures every node execution, shows intermediate state at each step, surfaces token usage per node, and helps identify retry storms. Cost: $39 per seat per month plus trace volume charges.
Langfuse is the self-hosted alternative. It supports LangChain through the standard callback interface, captures LlamaIndex retrieval events natively, integrates with LangGraph through OpenTelemetry, and runs on your infrastructure for approximately $25 per month. For sovereign deployments and for any team with EU data residency requirements, Langfuse is the correct choice.
OpenTelemetry is the foundation to instrument regardless of platform. Instrument at the framework callback level and at the infrastructure level. This gives you vendor-portable traces that work with any platform and enable custom dashboards in Grafana.
For EU AI Act Article 17: instrument OpenTelemetry traces to an append-only PostgreSQL table in your Frankfurt region cluster with 36-month retention. This is the technical implementation of the quality management requirement -- a database configuration you own, not a SaaS feature.
The Case for Staying Managed -- An Honest Counterargument
The sovereign stack recommendation in this post is correct for the right team at the right scale. Here is exactly when managed services are the better choice.
Your workload is under 1,000 daily queries and primarily simple document Q&A. The engineering overhead of maintaining a self-hosted Qdrant cluster, PostgreSQL checkpoint store, Langfuse instance, and LangGraph application adds up quickly. At small scale, that maintenance cost exceeds the $500 per month LlamaCloud subscription.
Your team has no prior experience managing production LLM infrastructure. The sovereign stack breaks in ways that require someone who knows what to do when Qdrant rebuilds an HNSW index under load, when PostgreSQL connection pools exhaust at 3am, or when a LangGraph version upgrade changes the checkpoint schema. Managed services provide a useful safety net while you build that experience.
Your time to production is under four weeks. LlamaCloud integration takes four days. The hybrid sovereign stack takes three to six weeks to build correctly. If the deadline matters more than the operational economics, start managed and migrate when the volume makes the threshold clear.
The $300 per month threshold is the decision line. Below it, managed services are the rational economic choice. Above it, the sovereign stack pays back within three months at most scales.
Kill Criteria — Do NOT Build the Sovereign Hybrid Stack If:
If your workload is deterministic, linear, and high-volume — classification, extraction, summarization at scale — direct API calls with lightweight orchestration often outperform both LangChain and LlamaIndex. Frameworks add overhead that is not necessary for non-agentic batch processing. Measure your ATR (Abstraction Tax Ratio) before committing to a framework for simple workloads.
When Managed SaaS Wins — An Honest Counterargument
LlamaCloud or a lightweight managed RAG service handles this more cost-effectively than a self-hosted stack. The engineering time to maintain Qdrant + PostgreSQL + Langfuse exceeds the cost savings at small scale.
LlamaCloud integration takes four days. The hybrid sovereign stack takes three to six weeks. Start managed, prove the use case, migrate at the $300/month trigger.
The hybrid stack assumes you already know what happens when GPU inference hits 100% utilization, when Qdrant HNSW rebuilds under load, and when LangGraph checkpoints conflict after a failed deployment. If you have not learned these yet, the managed path is the correct teacher.
If GDPR Article 44 does not apply and managed costs are below the crossover trigger, self-hosting provides no economic or compliance advantage. Stay managed.
The sovereign stack saves money and improves compliance architecture at scale. Below that scale, managed SaaS is a rational engineering choice — not a failure of judgment. The $300/month trigger is the line where the argument changes.
LangChain vs LlamaIndex Decision Matrix 2026 — By Use Case and Scale
| Use Case | Primary Choice | Monthly Cost (self-hosted) | Engineering Time | Sovereign? |
|---|---|---|---|---|
| Simple document Q&A (<1K queries/day) | LlamaCloud (managed) | $35-500/month | 4 days | ❌ Managed |
| Enterprise knowledge base (1K-10K queries/day) | LlamaIndex self-hosted + pgvector | ~$70/month | 1-2 weeks | ✅ Full |
| Multi-agent workflow with tool calling | LangGraph OSS + PostgreSQL | ~$150/month | 2-4 weeks | ✅ Full |
| Production RAG agents (most systems) | Hybrid: LlamaIndex + LangGraph | ~$150-220/month | 3-6 weeks | ✅ Full |
| EU regulated AI (any scale) | Hybrid + Article 14 HITL interface | ~$200-300/month | 6-10 weeks | ✅ Full |
| Air-gapped / on-premises | LlamaIndex + vLLM + Qdrant local | Infrastructure cost only | 4-8 weeks | ✅ Maximum |
| High-volume batch (classification/extraction) | Raw API calls + lightweight orchestration | Inference cost only | 1 week | ✅ Full |
Migration Blueprint — Managed LlamaCloud/LangSmith → Sovereign Hybrid Stack (3 Phases)
Deploy self-hosted stack alongside managed — dual-write, read from managed
Deploy LlamaIndex + LangGraph self-hosted alongside your existing managed service. Dual-write all operations. Read exclusively from managed. Compare outputs for 14 days across retrieval quality, agent state accuracy, and latency.
Phase 2 Trigger: Zero output differences for 48 consecutive hours on 10% traffic sampleRoute 10% → 50% → 100% traffic to self-hosted via load balancer weight
Shift traffic incrementally. Monitor retrieval precision, agent state correctness, latency P95, and error rate at each increment before proceeding.
Decommission managed — 7 days at 100% self-hosted with no rollback events
Export 90-day trace history from LangSmith/LlamaCloud (GDPR compliance). Cancel subscriptions. Delete data and obtain signed deletion certificates.
Break-even: 64 person-hours × $150 = $9,600 one-time. At $300/month savings vs managed, payback in under 2 months.
Frequently Asked Questions
What You Should Take Away from This Post
After reading this post, these are the decisions and actions that matter.
Your framework choice is a layer decision, not a product decision. LlamaIndex owns retrieval quality. LangGraph owns orchestration durability. Map each operational layer of your system to the tool designed for it before writing framework-dependent code.
Calculate your ORB score first. Low ORB means retrieval dominates start with LlamaIndex. High ORB means orchestration complexity dominates -- start with LangGraph. When both dimensions are non-trivial, build the hybrid stack.
The token overhead gap is $2,400 per month at 10 million requests. The self-hosted crossover for LlamaIndex is approximately 7,000 daily queries. The $300 per month managed cost threshold is where sovereign self-hosting becomes economically rational. These are scenario estimates run the numbers against your actual volume and model pricing.
Neither framework provides EU AI Act compliance. Build the governance layer confidence threshold routing, human override audit log, 36-month trace retention on top of whichever framework you choose. The enforcement deadline is August 2, 2026.
The six failure modes in this post each have a one-line code fix. All six are preventable before deployment. None require a framework change. They require a configuration decision.
The most revealing question in any LangChain vs LlamaIndex architecture review is not which framework is faster. It is: what happens when retrieval returns the wrong answer at the same moment that an agent enters a retry loop? In every production deployment I have reviewed, the teams that handled both failure modes gracefully were the ones who separated retrieval and orchestration into distinct layers from the beginning. The hybrid architecture is not a compromise between two frameworks. It is the recognition that retrieval quality and orchestration durability are two different engineering problems that happen to need to exist in the same system.
Every pattern I document in these posts comes from a real production system — a real architecture review, a real post-mortem, or a real cost conversation that happened after a tool choice was made before the production data existed. RankSquire publishes these patterns because the engineering community deserves production truth, not vendor marketing. The systems that fail are not built by careless engineers. They are built by capable engineers who did not have access to the numbers before they committed to the architecture.
Build the sovereign architecture before you need it. The cost of building it correctly on day one is measured in engineer-hours. The cost of rebuilding it at 10,000 production interactions is measured in weeks, migrations, and compounding errors that have already reached your users. Every post on RankSquire exists to give you the production truth before you commit to the architecture — not after.