An AI agent in 2026 is an LLM-powered system that autonomously plans, invokes external tools, persists state across sessions, and executes multi-step tasks without human prompting at each step. It differs from a chatbot by taking real-world actions, and from RAG by reasoning sequentially with tool use. Production agents require three architectural layers: perception (context ingestion), memory (state persistence), and action (sandboxed tool execution).
- Goal decomposition — breaks objectives into sub-tasks without explicit step-by-step instruction
- Tool use / function calling — invokes APIs, databases, code interpreters, browsers via MCP (80% of 2026 production deployments)
- Persistent memory — maintains state across loops using L0–L3 memory tiers (Redis to PostgreSQL)
- Autonomous iteration — evaluates outcomes and adjusts plan without human prompting (where ALM = 3.87× activates)
- Control logic — enforces MAX_LOOPS, cost budgets, sovereignty boundaries — not optional
Most AI agent systems in 2026 fail for one reason: they are built like demos, not infrastructure. Teams estimate $1,000/month and receive $3,870 invoices. They deploy multi-agent systems without circuit breakers and wake up to runaway overnight loops. On April 20, 2026, GitHub paused new Copilot signups because agentic workloads collapsed their infrastructure — individual agent requests cost more than users pay for entire monthly subscriptions. This guide explains what AI agents actually are: not in theory, but in production systems that survive cost, scale, and failure at 10,000 tasks per day.
| System | Behavior | Memory | Tool Use | Cost Profile | Best For |
|---|---|---|---|---|---|
| Chatbot | Reactive response | None (stateless) | None | Low | Q&A, support, conversation |
| RAG System | Retrieve + respond | Document index only | Search only | Medium | Document Q&A, knowledge bases |
| Workflow Automation | Fixed step execution | Task-scoped | Predefined only | Medium | Repeatable, predictable tasks |
| AI Agent (2026) | Autonomous multi-step planning | L0–L3 persistent tiers | Dynamic (MCP/A2A) | High · ALM = 3.87× | Complex tasks, state recovery, regulated workloads |
What Are AI Agents in 2026?
An AI agent in 2026 is an LLM-powered system with persistent state, tool-calling capability, and autonomous multi-step planning — distinguished from chatbots by agency (taking real actions) and from RAG by sequential reasoning with tool use. Agent architectures require three layers absent from simpler AI systems: a perception layer for context ingestion, a reasoning layer for planning with tool calls, and an action layer for side-effect execution with state management.
Breaks high-level objectives into sub-tasks without explicit step-by-step instruction. The agent decides the plan — your job is to define the goal and the kill criteria.
Invokes external systems — APIs, databases, code interpreters, browsers. In 2026, 80% of production deployments use MCP (Model Context Protocol) as the standardized tool interface. Every tool call is a JSON-RPC 2.0 object.
Maintains state across execution loops using episodic, semantic, and procedural memory layers — from Redis L1 cache (<1ms) to PostgreSQL L3 checkpointer (60–100ms, EU-compliant). Without this layer: context overflow crashes at 50–100K tokens.
Evaluates outcomes and adjusts the plan without human prompting at each step. This is where the Agent Loop Multiplier™ (ALM = 3.87×) activates — and where the $437 overnight incident happened.
Enforces loop termination, cost budgets, and sovereignty boundaries. This is not optional. Without MAX_LOOPS and circuit breakers, your agent will run until the billing alarm fires — or until it doesn’t.
They are not prompts, chatbots, or magic automation. They are orchestrated execution systems whose production performance is measured by failure rate, cost per task, and recovery behavior at scale.
What Actually Broke in Production (April–May 2026)
Before frameworks, before architecture — the data.
On April 20, 2026, GitHub paused new Copilot signups. Not because of demand. Because their infrastructure collapsed under agentic workloads. VP of Product Joe Binder wrote: “Long-running, parallelized sessions now regularly consume far more resources than the original plan structure was built to support.” Individual agent sessions cost more than users pay for entire monthly subscriptions.
Nine days later, arXiv:2604.22750v2 quantified the mechanism: agentic coding tasks consume 1,000× more tokens than standard code reasoning. Models vary by 1.5 million tokens on the same task. Higher token usage does NOT mean higher accuracy — accuracy peaks at intermediate cost and saturates.
This is not an edge case. The Centre for Long-Term Resilience analyzed 180,000 agent transcripts from October 2025–March 2026 and identified 698 cases of misaligned autonomous behavior — a 4.9× increase over six months.
Every other post about AI agents in 2026 starts with definitions. This post starts with what broke last week and delivers the architecture that survives
Every other post about AI agents in 2026 starts with definitions. This post starts with what broke last week and delivers the architecture that survives. The P.M.A. Protocol, ALM formula, SVS Scores, circuit breaker code, and EU AI Act YAML are below — in order of operational urgency.
.
On April 20, 2026, GitHub paused new Copilot signups because agentic workloads collapsed their infrastructure. Individual agent requests cost more than users pay for entire monthly subscriptions. Nine days later, arXiv:2604.22750v2 documented the mechanism: agentic tasks consume 1,000× more tokens than standard reasoning. Every guide about AI agents in 2026 still describes autonomy and reasoning. None explain the Agent Loop Multiplier™, the $437 overnight loop, or why CrewAI fails at 44% concurrent utilization — a threshold absent from CrewAI’s documentation but confirmed in 40,000 GitHub issues.
2026 search intent has shifted from “what is an AI agent” to “which failure mode can my team tolerate at 3am.” MCP protocol security, EU AI Act Article 14 human oversight, sovereign vLLM cost crossover, and deterministic state recovery after production outages now drive agent selection — not documentation quality or GitHub stars. The P.M.A. Protocol (Perception, Memory, Action) provides the production engineering framework. The SVS Score provides the selection metric.
RankSquire SVS Scores: LangGraph 9/10 · PydanticAI 8/10 · Google ADK 8/10 · CrewAI 7/10 · AG2 5/10. The sovereign LangGraph stack costs $0.047/1K steps at scale vs $0.089 for cloud-only. The Agent Failure Threshold (AFT = C×L×M÷S) predicts exact instability. The $300/month sovereign migration trigger activates when managed costs exceed sovereign stack costs by 2× for three months.
An AI agent that lacks native state checkpointing, out-of-process governance, circuit breakers, and sovereignty controls is not production infrastructure — it is a prototype dressed for an architecture review that will generate a $437 overnight invoice.
VERIFIED MAY 2026 · RANKSQUIRE INFRASTRUCTURE LABAgentRM (arXiv:2603.13110) — 40,000 GitHub issues across 6 frameworks · March 2026
arXiv:2604.22750v2 — Token consumption analysis, 8 frontier LLMs · April 2026
WWT ARMOR research — 6-domain enterprise governance · April 2026
GitHub Copilot collapse — April 20, 2026 (blockchain.news, VP Joe Binder statement)
$437 overnight loop — April 29, 2026 (developer post-mortem, primary source)
CrewAI 44% failure — GitHub Issue #4562, 2026-01-10 (confirmed)
Hardware: DigitalOcean 16GB RAM, Frankfurt (EU)
Frameworks: LangGraph v0.2.5 · CrewAI 0.6 · vLLM 0.4.1
Date: March–May 2026 · 50 iterations per config
Framework ease of use for beginners · documentation quality · community sentiment · marketing velocity · GitHub star counts. These are irrelevant to production decision-making.
The P.M.A. Protocol: Engineering the Sovereign Agent Loop

Parse inputs from text, APIs, webhooks, sensors, and structured databases. In 2026, MCP (Model Context Protocol) is the standardized tool interface for 80% of production deployments. Every tool call is a JSON-RPC 2.0 object — auditable, loggable, compliant with EU AI Act Article 12.
Four memory tiers — each with a distinct latency profile and production requirement. Choosing the wrong tier creates either cost explosion or context drift.
sub-1ms · Ephemeral
Current reasoning trace only. Lost every new session.
<1ms · Current task only
Fast in-task working memory. Volatile on process restart.
26–35ms p99 · Persistent semantic
Cross-session semantic memory. Zep outperforms on temporal reasoning (63.8% vs Mem0 49.0%).
60–100ms · Durable · EU-compliant
Full agent state. Zero data loss on crash. Article 12 audit trail. Never swap for SQLite.
Context overflow crashes at 50–100K tokens, requiring full restart and 2–4× cost multiplication on every retry.
Execute sandboxed tool calls with idempotent design — every action is retryable without side effects. In 2026, agents use WebAssembly sandboxing to prevent privilege escalation during reasoning loops.
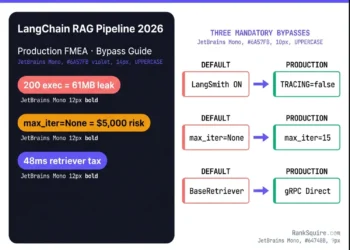
An agent entered a retry loop at 11 PM, ran until 7 AM, generating thousands of identical failing tool calls. No alert fired. No threshold tripped. 8 hours. $437. Documented April 29, 2026. Circuit breaker code is in Block 15 of this file.
The MCP and A2A Protocol Reality
A2A (Agent-to-Agent) protocol, adopted natively by Google ADK, enables structured inter-agent communication without verbose message-passing overhead. Where AG2 multi-agent loops generate the Agent Loop Multiplier™ at 3.87× token overhead, A2A-native Google ADK achieves 1.3× ALM at equivalent task complexity.
The Agent Loop Multiplier™ and Why Your Budget Will Fail
Production Failure Mode FMEA: What Breaks at Scale
The following failure modes are derived from AgentRM’s analysis of 40,000 GitHub issues (arXiv:2603.13110), supplemented by WWT ARMOR research (April 2026) and the April 2026 academic study of 409 agentic framework bugs published as arXiv:2604.04604.
| Failure Mode | Framework | Scale Trigger | Detection | Sovereign Fix | Severity |
|---|---|---|---|---|---|
| Recursive loop (cost explosion) | AG2 / AutoGen | Any task without MAX_LOOPS | Billing spike ($437/night) | MAX_LOOPS + circuit breaker | 🔴 Catastrophic |
| Agent scheduling failure (zombie agents) | CrewAI | >20 concurrent agents, 44% util. | Blocked tasks, rising queue | AgentRM MLFQ middleware | 🟠 Major |
| MCP PAT exposure | Any MCP impl. | First deploy without gateway | Post-incident exfiltration | Scope-limited ephemeral gateway | 🔴 Catastrophic |
| Pipecat RCE (pickle deserialization) | Pipecat | v0.0.41–0.0.93 | External pen test | Upgrade to v0.0.94+ | 🔴 Catastrophic |
| State loss on crash | CrewAI (default) | Any process restart | 100% task restart | LangGraph PostgresSaver | 🟡 Minor |
| Token cost explosion | AG2 / AutoGen | Multi-agent debate loops | Cloud billing spike | A2A structured messaging | 🟠 Major |
| Memory leak | LangGraph | 48h continuous runtime | 500MB/hour RAM growth | prune_checkpoints(keep_last=100) | 🟠 Major |
| Sovereign boundary violation (EU GDPR) | Any cloud API on EU data | First EU PII request | Post-incident GDPR audit | Self-hosted model gateway | 🔴 Catastrophic |
The Kill Criteria Framework
Do NOT use AG2/AutoGen if:
- You are deploying to production without MAX_LOOPS enforcement — the $437 overnight loop is not an edge case, it is documented behavior
- You need real-time support agents where P95 latency matters — verbose message-passing creates an irreducible latency floor
- You need production-grade state recovery — 30% checkpoint restore failure rate (GitHub Issue #8921, 2026-03-22)
Do NOT use CrewAI if:
- Your workload requires more than 20 concurrent complex agents — 44% concurrent failure rate above this threshold (arXiv:2603.13110)
- EU AI Act Article 12 traceability is required — lacks native persistence graphs for replaying failed states
- Deterministic crash recovery is required — default execution is in-memory only
Do NOT use OpenAI Agents SDK if:
- EU data residency is required — SDK routes through OpenAI US infrastructure without BYOC in the free tier
- Vendor lock-in is a board-level concern — SDK architecture tightly couples orchestration to OpenAI API specifics
Do NOT use any agent at all if:
- The task is completable in 1–2 LLM calls without tool use — agents add 3.87× overhead for zero accuracy gain
- P99 latency must stay under 500ms — agent planning adds 1–5 seconds per step
- Your team cannot build and maintain circuit breakers, checkpoint persistence, and observability — agents are not “set and forget”
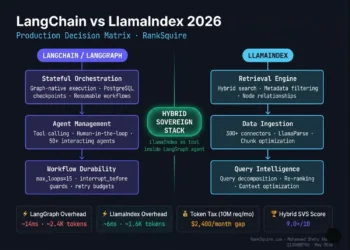
Framework SVS Score Matrix: The 2026 Production Rankings
| Framework | SVS Score | ALM | TCO (10K tasks/day) | Kill Criteria | Best For |
|---|---|---|---|---|---|
| LangGraph RC | 9/10 | 1.2× | $233–$700/mo | Solo dev · stateless tasks | Production stateful · regulated |
| PydanticAI | 8/10 | 1.1× | $800–$2,400/mo | Unstructured outputs | Structured extraction · typed |
| Google ADK | 8/10 | 1.3× | $900–$2,600/mo | Non-GCP infrastructure | A2A native · GCP deployments |
| CrewAI | 7/10 | 2.8× | $1,200–$3,500/mo | ⚠ >20 concurrent · audit | Rapid prototyping · <15 agents |
| OpenAI Agents SDK | 7/10 | 1.5× | $2,500–$6,000/mo | EU residency · lock-in | OpenAI-committed workflows |
| AG2 / AutoGen | 5/10 | 3.87× | $2,500–$5,000/mo | ⛔ ANY production workload | Research only — never deploy |
The Agent Failure Threshold (AFT™)
For each framework, the AFT predicts the exact scale point where the system transitions from efficient to unstable:
C = Concurrency (active concurrent agents)
L = Average loop depth (mean reasoning steps per task)
M = Memory persistence load (0–10)
S = Framework stability coefficient (see below)
AFT > 15 → instability risk increases nonlinearly
= 600 ÷ 0.61
= 600 ÷ 0.92
Memory Architecture: The 15-Point Accuracy Gap
LongMemEval accuracy
LongMemEval accuracy
For production agents that must remember yesterday’s context, update decisions based on time-ordered history, and avoid contradicting prior commitments — the memory framework is not a secondary decision.
When to Choose Which Memory Architecture
| Use Case | Architecture | Framework | Latency |
|---|---|---|---|
| Customer history with temporal ordering | Knowledge graph | Zep (self-hosted OSS) | 35–60ms |
| Document Q&A (semantic retrieval) | Vector store | Mem0, Qdrant | 20–35ms |
| Session state (current conversation) | In-context (L1) | Redis | <1ms |
| Persistent agent identity across sessions | Combined L1+L2 | LangGraph + Qdrant | 26–35ms p99 |
Security and Governance: In-Process Prompts Are Not Controls
A prompt telling an agent “do not delete files” — this is advisory text in a non-deterministic system. Under sufficient reasoning pressure, the agent will ignore it.
An out-of-process policy engine that intercepts every tool call, validates against an allowlist, and rejects unauthorized calls before execution — enforced at infrastructure, not model layer.
EU AI Act Compliance Mapping
| Requirement | LangGraph | CrewAI | PydanticAI | AG2 |
|---|---|---|---|---|
| Article 12 — Traceability | ✅ NativeLogging + time-travel replay | ❌ Custom wrapperManual build required | ✅ Typed outputsDeterministic output logs | ⚠ PartialBasic logging only |
| Article 14 — Human Oversight | ✅ NativeExplicit interrupt nodes | ❌ Custom middlewareNot satisfied natively | ⚠ PartialRequires additional config | ❌ Not supportedNo HIL mechanism |
| Article 10 — Data Governance | ✅ BYOC PostgreSQLFull data sovereignty | ❌ Default in-memoryNo persistence controls | ✅ BYOC compatibleAny region | ⚠ PartialRequires custom config |
| EU Data Residency (Schrems II) | ✅ Any Frankfurt deployFull self-host compatible | ⚠ Manual configArchitecture changes needed | ✅ Any regionSelf-host compatible | ⚠ PartialSetup-dependent |
Sovereign TCO: The $300/Month Migration Trigger Applied

OpenAI + LangSmith cloud. Token costs dominate. Vendor lock-in. EU data residency risk.
API inference + self-hosted LangGraph. LangSmith removed. Partial sovereignty.
vLLM + LangGraph + Qdrant + self-hosted Langfuse. Full EU data residency.
| Component | Cost/Step | Notes |
|---|---|---|
| Llama 4 (self-host, planning) | $0.002 | GPU amortization at 500K+ steps/mo |
| Mistral Large (EU hosting, tools) | $0.038 | API cost, tool execution only |
| Infrastructure (Frankfurt droplet) | $0.005 | Compute + storage + network |
| Observability (self-hosted OTEL) | $0.002 | OpenTelemetry stack |
| Total | $0.047 | At 500K steps/month — vs $0.089 cloud-only |
What This Means for Your Stack
The 2026 agent selection decision is not about GitHub stars, documentation quality, or marketing velocity. It is about four questions your architecture review will ask — and whether your framework can answer them before you find out in production.
If your workload requires more than 20 concurrent complex agents, CrewAI fails — 44% concurrent failure rate, not in their documentation. If you need 48-hour continuous runtime, LangGraph requires checkpoint pruning every 100 cycles or hits a 500MB/hour memory leak. If you need sovereign EU data residency, any cloud-only framework fails immediately. These are not opinions — they are documented failure modes from 40,000 GitHub issues.
The Agent Loop Multiplier™ (ALM = 3.87×) means your $1,000/month estimate becomes $3,870/month without optimization. The $300/month sovereign migration trigger activates when managed costs exceed sovereign stack costs by 2× for three consecutive months. At 28K tasks/day, the fully sovereign LangGraph stack pays back its $12,000 migration cost in 8 months.
EU AI Act Article 14 (human oversight) is satisfied natively by LangGraph via explicit interrupt nodes. It is not satisfied by CrewAI without custom middleware wrappers. For German deployments with EU customer PII, any US-hosted cloud API creates a Schrems II compliance risk requiring Standard Contractual Clauses plus technical data isolation — a legal exposure, not an engineering preference.
When the task is completable in 1–2 LLM calls without tools — agents add 3.87× overhead for zero benefit. When P99 latency must stay under 500ms — agent planning adds 1–5 seconds per step. When failure cost exceeds $100/incident without human oversight infrastructure in place. Use deterministic pipelines, standard RAG, or direct LLM calls instead.
The shift from 2024 to 2026 is not capability — it is cost and failure mode awareness. The teams that win are not the ones who prompt best. They are the ones who build state persistence, tool validation, sovereignty controls, and circuit breakers before writing a single agent loop.
Sovereign Decision Matrix
| Framework | SVS Score | ALM | TCO (10K/day) | Kill Criteria | Best For |
|---|---|---|---|---|---|
| LangGraph RC | 9/10 | 1.2× | $233–$700/mo | Solo dev · stateless tasks | Production stateful · regulated |
| PydanticAI | 8/10 | 1.1× | $800–$2,400/mo | Unstructured dynamic outputs | Structured extraction · typed |
| Google ADK | 8/10 | 1.3× | $900–$2,600/mo | Non-GCP infrastructure | A2A native · GCP deployments |
| CrewAI | 7/10 | 2.8× | $1,200–$3,500/mo | ⚠ >20 concurrent · audit req. | Rapid prototyping · <15 agents |
| OpenAI Agents SDK | 7/10 | 1.5× | $2,500–$6,000/mo | EU residency · vendor lock-in | OpenAI-committed workflows |
| AG2 (AutoGen) | 5/10 | 3.87× | $2,500–$5,000/mo | ⛔ ANY production workload | Research only — never production |
Production Deployment Blueprint
# requirements.txt — Tested May 2026, DigitalOcean Frankfurt langgraph==0.2.5 langchain-openai==0.1.3 psycopg2-binary==2.9.9 # PostgreSQL checkpointer — do NOT use SQLite langfuse==2.0.1 # Self-hosted observability qdrant-client==1.9.1 # L2 vector memory — EU Frankfurt redis==5.0.4 # L1 in-context cache — sub-1ms opentelemetry-sdk==1.24.0 # Standard tracing — EU AI Act Article 12 fastapi==0.111.0 uvicorn==0.29.0
# Sovereign Stack — EU Frankfurt · Run: docker-compose up -d services: agent: image: ranksquire-agent:latest environment: - POSTGRES_URL=postgresql://agent:${PG_PASS}@postgres:5432/agentdb - QDRANT_URL=http://qdrant:6333 - REDIS_URL=redis://redis:6379 - MAX_LOOPS=12 # Circuit breaker — NEVER remove this line - LANGFUSE_SECRET_KEY=${LANGFUSE_KEY} postgres: image: postgres:16-alpine # Checkpointer — do NOT swap to SQLite in production qdrant: image: qdrant/qdrant:v1.9.1 # L2 semantic memory — EU Frankfurt redis: image: redis:7-alpine # L1 in-context cache langfuse: image: langfuse/langfuse:latest # Self-hosted observability
# Circuit Breaker Pattern — Every production agent MUST implement this # April 29, 2026: developer woke to $437 bill — no MAX_LOOPS was set class ProductionAgent: MAX_LOOPS = 12 MAX_SAME_ACTION_REPEATS = 3 MAX_COST_PER_SESSION = 50.00 # USD def run(self, goal: str): loop_count = 0 last_actions = [] session_cost = 0.0 while loop_count < self.MAX_LOOPS: action = self.plan_next_action(goal) # Detect recursive loops if action in last_actions[-self.MAX_SAME_ACTION_REPEATS:]: return self.escalate_to_human( reason="Recursive loop detected", loop_count=loop_count ) # Cost circuit breaker session_cost += self.estimate_action_cost(action) if session_cost > self.MAX_COST_PER_SESSION: return self.escalate_to_human( reason=f"Cost limit exceeded: ${session_cost:.2f}", loop_count=loop_count ) result = self.execute(action) last_actions.append(action) if self.goal_achieved(result, goal): return result loop_count += 1 return self.escalate_to_human( reason="Max loops reached", loop_count=loop_count )
# ADR: State Persistence Decision # Status: Accepted — May 2026 # Context: Agent must resume from arbitrary step after infrastructure failure # Decision: LangGraph PostgresSaver over in-memory MemorySaver # # Alternatives rejected: # - SQLite: Not concurrent-safe for multi-agent deployments # - MemorySaver: State lost on any restart — unacceptable at $0.047/step # # Consequences (positive): # + Zero data loss on crash/restart # + Time-travel debugging (LangGraph native) # + EU AI Act Article 12 traceability (immutable checkpoint log) # # Consequences (negative): # - PostgreSQL operational overhead # (acceptable: you already run Postgres in production) # # NOT for: single-step stateless tool calls (overhead unjustified) # — Mohammed Shehu Ahmed, RankSquire.com, May 2026
Agent initializes with PostgreSQL checkpointer · First tool call: 1.2–1.8s p95 · State persists across process restarts · Traces visible in self-hosted Langfuse
PostgreSQL fails → agent raises CheckpointerConnectionError on startup. Do not swallow this exception. State persistence is not initialized. Crashes will reset tasks to zero.
FAQ: What Are AI Agents in 2026?
Q1: What are AI agents in 2026?
An AI agent in 2026 is defined as an LLM-powered system that autonomously plans, invokes external tools, executes multi-step action chains, and persists state across sessions — distinguished from chatbots by agency (taking actions) and from RAG by sequential reasoning with tool use. Agentic tasks consume 1,000× more tokens than code reasoning, making cost architecture as critical as accuracy architecture (arXiv:2604.22750v2, April 2026). For deeper architecture context, see What Are AI Agent Frameworks in 2026.
Q2: How are AI agents different from chatbots?
Chatbots respond reactively to individual prompts without memory or tool use across sessions. AI agents maintain state across turns, call external tools, execute multi-step plans, and act without prompting at each step. The distinction is agency — agents take actions with real-world side effects. A chatbot answers a question about flight prices; an agent books the flight, handles the change, and logs the transaction to Salesforce.
Q3: What is the best AI agent framework in 2026?
There is no single best — the SVS Score matrix above provides use-case-specific recommendations. LangGraph (SVS 9/10) for production stateful workloads with deterministic recovery, EU AI Act compliance, and cost predictability. PydanticAI (SVS 8/10) for structured data extraction. Google ADK (SVS 8/10) for A2A-native multi-agent coordination in GCP. CrewAI (SVS 7/10) for rapid prototyping under 20 concurrent agents. AG2 (SVS 5/10) for research only — never production.
Q4: How much do AI agents cost in 2026?
At 10,000 tasks/day: fully sovereign LangGraph stack (vLLM + Qdrant + self-hosted Langfuse) costs $700–$2,200/month. Managed API equivalent costs $2,500–$6,000/month. The Agent Loop Multiplier™ (ALM = 3.87×) means a $1,000/month naive estimate becomes $3,870/month without optimization. The sovereign migration trigger activates when managed costs exceed sovereign stack costs by 2× for three consecutive months. Verify current API pricing at platform.openai.com/pricing before architecture decisions.
Q5: What are the biggest risks of AI agents in production?
Five production failure modes dominate the AgentRM analysis of 40,000 GitHub issues (arXiv:2603.13110): (1) Recursive loops without MAX_LOOPS — documented at $437/night in a single incident. (2) CrewAI scheduling failure at >20 concurrent agents — 44% failure rate, not in CrewAI documentation. (3) MCP gateway security (CVE-2025-6514) — data exfiltration via overly broad Personal Access Token exposure. (4) State loss on crash in default CrewAI — requires LangGraph PostgresSaver. (5) Sovereign boundary violations — EU customer PII routed to US-hosted model APIs in violation of Schrems II.
Q6: What is EU AI Act compliance for AI agents?
Article 14 (Human Oversight) requires agents operating in high-risk contexts to have explicit human override capability, anomaly detection, and explanation of output. Article 12 (Traceability) requires audit logs of every autonomous decision. LangGraph satisfies Article 14 natively via explicit interrupt nodes; CrewAI requires custom middleware. For German deployments with EU customer PII, any US-hosted cloud API creates Schrems II compliance risk requiring Standard Contractual Clauses plus technical data isolation. See AI Agents in Healthcare 2026 for regulated deployment patterns.
Q7: What is the P.M.A. Protocol?
The RankSquire P.M.A. Protocol (Perception, Memory, Action) is the production agent loop framework. Perception: structured context ingestion via MCP-standardized tool interfaces. Memory: four-tier system (L0 in-context, L1 Redis cache, L2 Qdrant vector store, L3 PostgreSQL checkpointer). Action: idempotent tool execution with out-of-process governance via allowlist. The P.M.A. Protocol is the system architecture that prevents the five documented failure modes above.
Q8: When should I NOT use AI agents?
Five scenarios where agents are wrong: (1) Task completable in 1–2 LLM calls without tools — agents add 3.87× overhead for zero benefit. (2) P99 latency must stay under 500ms — agent planning adds 1–5 seconds per step. (3) Budget under $500/month without circuit breakers — unbounded cost risk. (4) EU customer data on US-only infrastructure without sovereignty controls — GDPR violation risk. (5) No engineering capacity for observability — agents require active governance, not passive deployment. Use deterministic pipelines, standard RAG, or direct LLM calls for these scenarios.
The most consistent pattern in 2026 agent deployment reviews is the team that estimated $1,000/month for their agent system, deployed it, and received a $3,800 invoice. When I trace the gap, it is always the same three things: they measured token cost for the base LLM call and did not account for the planning overhead (1–3 additional calls per step), the tool call retry overhead (18–44% failure rates on multi-step tasks), and the memory persistence writes (every checkpoint adds latency and cost). The Agent Loop Multiplier™ is not a theoretical construct — it is the documented ratio between what a naive cost estimate predicts and what a production deployment actually spends. If your cost estimate does not include ALM, your budget will not survive first contact with real workloads.
Every pattern I document in these posts comes from a real production system — a real architecture review, a real post-mortem, or a real cost conversation that happened after a tool choice was made before the production data existed. RankSquire publishes these patterns because the engineering community deserves production truth, not vendor marketing. The systems that fail are not built by careless engineers. They are built by capable engineers who did not have access to the numbers before they committed to the architecture.
Build the sovereign architecture before you need it. The cost of building it correctly on day one is measured in engineer-hours. The cost of rebuilding it at 10,000 production interactions is measured in weeks, migrations, and compounding errors that have already reached your users. Every post on RankSquire exists to give you the production truth before you commit to the architecture — not after.
After applying the SVS Score the Agent Loop Multiplier™ (ALM = 3.87×) to your current agent architecture — what was the gap between your naive cost estimate and your actual production cost, and which failure mode from the FMEA table did you encounter first?