Agent Memory vs RAG — The Scale Threshold Analysis
Asking what breaks at scale is the wrong question to ask after you have already deployed. It is the right question to ask before your agent processes its ten-thousandth interaction and starts confidently producing outputs from corrupted context.
Both systems fail. They fail differently. They fail at different scale thresholds. And the failure modes are invisible until production load triggers them.
TL;DR: Quick Summary
RAG Precision
Recall drops below 80% as the retriever returns semantically similar but contextually wrong passages.
Memory Correctness
Stores accumulate conflicting and outdated beliefs retrieved with full confidence.
Retrieval Latency
Retrieval adds 50–200ms per step; a 10-step agent chain compounds into 2,000ms of pure overhead.
Structural Necessity
Neither system alone is correct. Hybrid is the minimum viable architecture for production scale.
Key Takeaways Architecture Analysis
RAG Precision failure
Vector similarity search returns the top-k most similar passages not the most relevant ones without a reranker.
Agent Memory failure
Conflicting and outdated records systematically degrade output quality once consolidation is missing.
Latency Compounding
A 100ms retrieval step in a 20-step agent chain results in 2,000ms of overhead per cycle.
Multi-Agent Conflicts
Two agents writing conflicting conclusions to the same namespace create equal retrieval weights for both claims.
Quick Answer Stated Directly
RAG Precision
Corpus growth degrades recall. The retriever returns plausible but wrong passages; the agent reasons correctly from incorrect context.
Memory Correctness
History without consolidation fills with conflicting beliefs. The agent retrieves stale info at full confidence with no error signal.
RAG breaks first on latency (compounds across agent steps immediately). Agent memory breaks first on correctness (degrades gradually, invisibly).
Precise Architecture Definitions
Agent Memory
The persistent, evolving knowledge store tied to an agent’s identity across sessions. It contains what the agent has learned, decided, and concluded — not external documents, but the agent’s own history of reasoning and action.
RAG (Retrieval-Augmented Generation)
Stateless external knowledge retrieval. On each query, the agent searches a fixed document corpus, retrieves the most similar passages, and injects them into the current context window. The corpus does not change with the agent’s experience.
The distinction matters for scale analysis: agent memory degrades with agent experience (interaction count). RAG degrades with corpus size. Both scale thresholds exist in every production deployment — regardless of vendor marketing.
Executive Summary: The Scale Failure Problem
Most AI agent deployments are prototyped with small corpora and short interaction histories. RAG works at 10K vectors. Agent memory works at 100 interactions. The demo is clean because neither scale threshold has been crossed.
Production load crosses both. By the time an enterprise agent has processed 50K interactions against a 2M vector corpus, it is operating with sub-80% retrieval recall and a memory store containing thousands of conflicting beliefs.
From assuming both systems scale linearly — which they do not — to understanding the specific corpus sizes and interaction counts at which each system’s failure mode activates. Build the hybrid architecture that prevents both from triggering simultaneously.
A production agent memory architecture where RAG handles external document retrieval within controlled limits, agent memory handles persistent identity with active consolidation, and the context window carries only the current session.
Defining the Two Systems
The failure modes at scale follow directly from design intent. Understanding where they diverge is the first step toward stability.
Persistent, evolving, and tied to identity. Accumulates experience and prior reasoning across session boundaries.
Demand-driven retrieval from a fixed document corpus. No session context or learning persists by default.

What Breaks in RAG at Scale
RAG failures are architectural activations that trigger as corpus size and query frequency grow. Five modes dominate production deployments above 100K vectors.
01. Context Window Saturation
At 500K vectors, cosine similarity returns semantically similar but contextually wrong passages. Increasing k to 20 passages adds 10,000 tokens per step—consuming context windows before reasoning begins.
02. Relevance Degradation
Without a reranker, recall drops below 80% at 500K vectors. At least 1 in 5 passages is contextually wrong, yet the agent has no signal to distinguish them.
03. Staleness & Consistency
Documents update, but embeddings are static. Outdated specifications are retrieved with the same confidence as current ones, leading to “confident hallucinations.”
04. Latency Compounding
Retrieval adds 50–200ms per step. In a 20-step agent chain, this creates 3,000ms of pure overhead before LLM reasoning even starts.
05. Corpus Contamination
RAG cannot distinguish authoritative documents from speculative ones. Contradictory passages are injected with equal weight, forcing reasoning from internal conflict.
| Retrieval Configuration | Recall at 500K+ Vectors |
|---|---|
| Vector Search (No Reranker) | < 80% Recall |
| Vector Search + Cross-Encoder | > 90% Precision |
| Payload Pre-filtering (Qdrant) | Scalable Precision |
The Strategic Framing: Agent memory vs RAG is not a binary choice. RAG answers “what does the external corpus say?” Agent memory answers “what have I previously decided?” The hybrid architecture composes both to maintain 90%+ reliability.
What Breaks in Agent Memory at Scale
Agent memory failures are silent and compounding. While RAG returns wrong passages, memory returns wrong beliefs that are indistinguishable from facts.
01. Memory Pollution & Hallucination Amplification
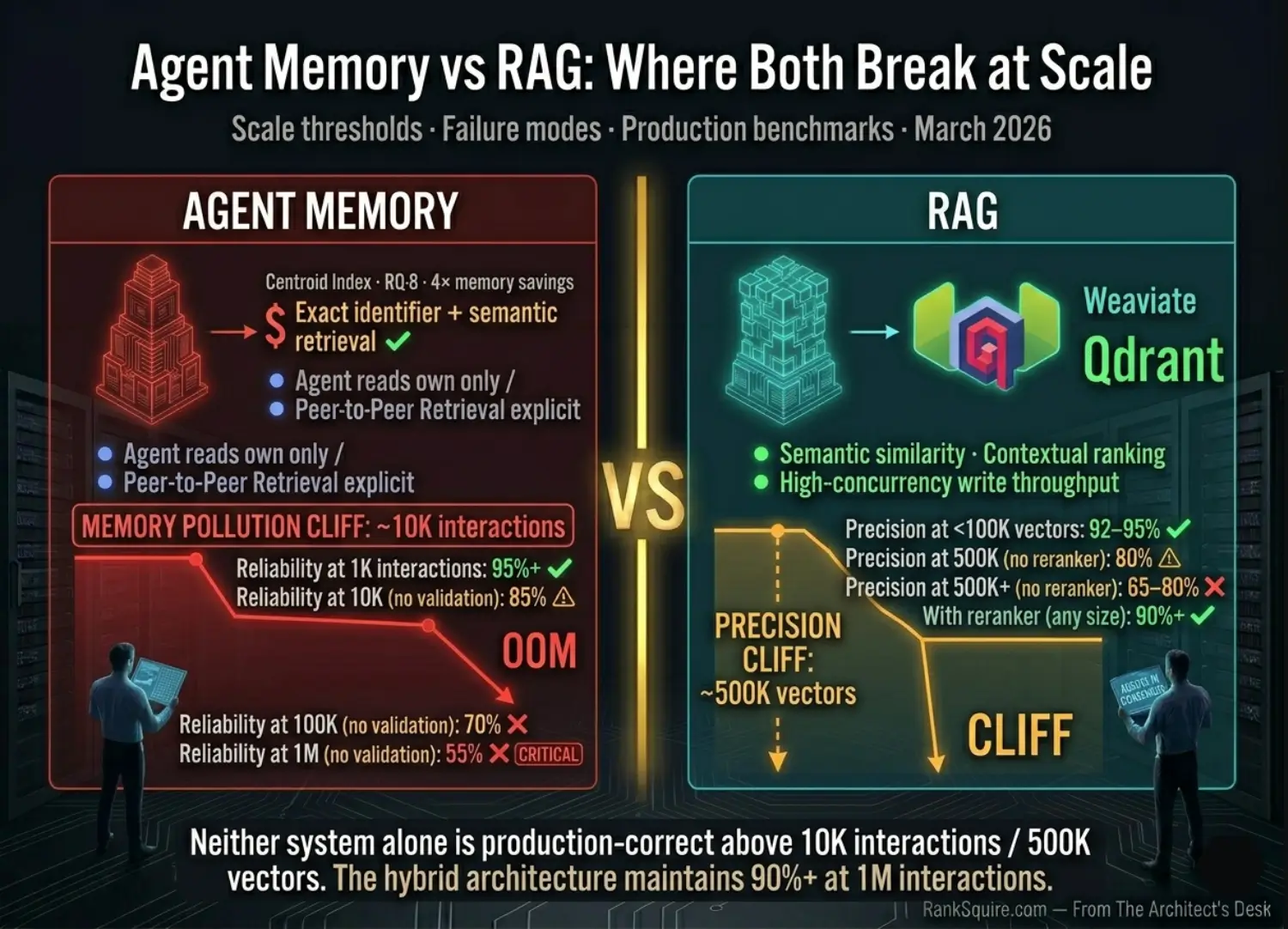
Incorrect conclusions from early sessions are stored as “established facts.” Later, the agent retrieves these errors as context for new reasoning, creating a loop of compounded misinformation by 5K–10K interactions.
02. Token Cost Explosion
Naive implementations that summarize full interaction histories scale costs linearly. At 10K interactions, full-history processing costs more than the total infrastructure budget.
03. The Forgetting Curve (Temporal Decay)
Cosine similarity ignores recency. An agent may retrieve a decision from 3,000 sessions ago that is semantically similar but contextually irrelevant to the current state.
04. Multi-Agent Write Conflicts
In shared namespaces, different agents may write contradictory conclusions about the same entity. Retrievals return both as equal weight context, forcing unpredictable reasoning.
05. Memory Overfitting
Extreme density in a narrow task domain causes the agent to ignore new context in favor of prior experience, leading to coherent but “locked-in” incorrect outputs.
| Architecture Status | Reliability Threshold (Interactions) |
|---|---|
| Unvalidated Writes (No Gate) | ~5K – 10K (Unreliable) |
| No Recursive Summarization | ~10K (Cost Failure) |
| Pure Cosine (No Time-Weighting) | ~1K (Context Drift) |
| Full Sovereign Memory Stack | 1M+ (Scalable) |
| Metric | 1K Interactions | 10K Interactions | 100K Interactions | 1M Interactions |
|---|---|---|---|---|
| RAG Retrieval Precision (Corpus Size Dependent) | ||||
| Corpus <100K vectors | 92–95% | 90–93% | 85–90%* | 80–85%* |
| Corpus 100K–500K vec | 88–92% | 85–90% | 78–83%* | 72–78%* |
| Corpus 500K+ vectors | 85–88% | 80–85%* | 72–78%* | 65–72%* |
| With reranker (any size) | 93–96% | 92–95% | 91–94% | 90–93% |
| Agent Memory Accuracy (History Dependent) | ||||
| Without validation gate | 95%+ | 85–90%* | 70–80%* | 55–70%* |
| With validation gate | 95%+ | 93–95% | 91–94% | 90–93% |
| With decay + time-weighting | 95%+ | 94–96% | 92–95% | 91–94% |
| Retrieval Latency (Per Step) | ||||
| RAG (no reranker) | 20–50ms | 25–60ms | 40–100ms | 80–200ms |
| RAG (with reranker) | 40–100ms | 50–120ms | 60–150ms | 100–250ms |
| Agent memory (Qdrant L2) | 20–29ms | 22–31ms | 24–33ms | 26–35ms |
| In-context (L1 Redis) | <1ms | <1ms | <1ms | <1ms |
| Overall System Reliability | ||||
| RAG only | High | High | Medium* | Low* |
| Agent memory only | High | Medium* | Low* | Critical* |
| Hybrid architecture | High | High | High | High |
Benchmark: Memory vs RAG at Scale
| Metric | 1K Int. | 10K | 100K | 1M |
|---|---|---|---|---|
| RAG Retrieval Precision | ||||
| Corpus < 100K vec | 92–95% | 90–93% | 85–90%* | 80–85%* |
| Corpus 500K+ vec | 85–88% | 80–85%* | 72–78%* | 65–72%* |
| With Reranker | 93–96% | 92–95% | 91–94% | 90–93% |
| Agent Memory Accuracy | ||||
| No Validation | 95%+ | 85–90%* | 70–80%* | 55–70%* |
| Validation Gate | 95%+ | 93–95% | 91–94% | 90–93% |
| Decay + Time-Wt | 95%+ | 94–96% | 92–95% | 91–94% |
| Retrieval Latency | ||||
| RAG (no rerank) | 20–50ms | 25–60ms | 40–100ms | 80–200ms |
| Agent Memory | 20–29ms | 22–31ms | 24–33ms | 26–35ms |
| L1 Context (Redis) | <1ms | <1ms | <1ms | <1ms |
| Token Cost / Session | ||||
| Naive Memory | Low | Medium | High* | Critical* |
| Recursive Sum | Low | Low | Low–Med | Medium |
Executive Findings
- The RAG Precision Cliff: Accuracy drops below 80% at 500K vectors without reranking; a reranker is mandatory for production agentic search.
- Pollution Saturation: Unvalidated agent memory degrades accuracy to 55% at 1M interactions. The Fix: Implement a validation gate or recursive summarization.
- Performance Winner: Hybrid architecture (Qdrant L2 + Redis L1) maintains 90%+ reliability without exponential latency spikes.
The Hybrid Architecture — Production Standards 2026
At scale (>10K interactions / 500K vectors), binary choices between RAG and Memory fail. Hybrid composition is the minimum viable infrastructure for production agents.
L1: In-Context 0ms
- HOLD: Task state & session vars
- LIVE: Context Window (128K+)
- TTL: Session duration only
L2: Agent Memory 26-35ms
- HOLD: Validated decisions & history
- LIVE: Qdrant / Redis
- TTL: Persistent (Validation Gates)
L3: RAG 50-250ms
- HOLD: External specs & compliance
- LIVE: Managed Vector Index
- TTL: Document-driven updates
L4: Summarization n8n
- DO: Recursive record compression
- RUN: Scheduled / Triggered
- AIM: Fixed token overhead
Conclusion: The Scale Failure Reality
Agent memory vs RAG — what breaks at scale is not a theoretical question. It has specific thresholds: RAG precision drops below 80% at 500K vectors without a reranker; Agent memory accuracy drops below 85% at 10K interactions without a validation gate. Both failures are silent, compound over time, and produce no error messages.
The binary framing — memory or RAG — is the wrong question. The correct focus is composition: RAG for external documents, agent memory for experience, in-context for current session state, and recursive summarization to keep retrieval clean at any volume.
The hybrid architecture delivers 90%+ reliability at 1M interactions. Neither system alone approaches this at scale. The investment is one engineer-day on DigitalOcean sovereign infrastructure; the cost of neglect is quality degradation from the 10,000th interaction onward.
7. FAQ: AGENT MEMORY VS RAG WHAT BREAKS AT SCALE 2026
Q1: What is the difference between agent memory and RAG at scale?
At scale, agent memory vs RAG — what breaks at scale diverges
significantly. RAG precision degrades as corpus size grows —
cosine similarity retrieval becomes less accurate above 500K
vectors without reranking, dropping below 80% recall in
production testing. Agent memory accuracy degrades as
interaction history grows — without validation gates and
consolidation, incorrect beliefs accumulate and are retrieved
with full confidence above 10K interactions. RAG fails on
external knowledge precision. Agent memory fails on internal
belief correctness. The failure modes do not overlap.
Q2: At what corpus size does RAG stop being reliable without a reranker?
RAG retrieval precision without a cross-encoder reranker drops
below 80% recall at approximately 500K vectors in production
AI agent deployments. Below 100K vectors, cosine similarity
retrieval maintains 88–95% precision for most query types.
Between 100K and 500K vectors, precision degrades noticeably.
Above 500K vectors, a cross-encoder reranker is required to
maintain 90%+ precision at production query frequency. Adding
a reranker restores precision to 91–94% at 1M+ vectors — at
the cost of 40–100ms additional latency per retrieval step.
Q3: How does memory pollution happen in agent memory systems?
Memory pollution occurs when an agent writes incorrect
conclusions to its long-term memory store. These incorrect
conclusions — produced by a prior wrong retrieval, an LLM
error, or incomplete context — are stored with the same
confidence metadata as correct ones. On future sessions, the
agent retrieves them as established fact and reasons from
them, generating further incorrect conclusions that are
themselves stored and retrieved.
The error compounds over
time without a visible failure signal. By 10K interactions
without a validation gate, a measurable fraction of the
memory store contains incorrect beliefs retrieved at full
confidence. The fix is architectural: a validation gate that
routes all agent outputs to a staging collection before they
enter the long-term retrieval pool.
Q4: How does the hybrid architecture prevent both RAG and memory failures?
The hybrid architecture in agent memory vs RAG — what breaks
at scale — assigns each retrieval problem to the system
optimized for it. In-context memory handles current session
state (zero latency, no retrieval overhead). Agent memory
handles persistent agent decisions and experience (Qdrant L2,
26–35ms, validation gate prevents pollution).
RAG handles
external document retrieval (separate Qdrant collection with
reranker at scale above 500K vectors). Recursive summarization
prevents memory token cost explosion by compressing older
records progressively. Routing logic in n8n determines which
layer handles each query — the agent does not choose.
Q5: Why does RAG latency compound so destructively in agent pipelines?
RAG latency compounds in agent pipelines because each reasoning
step triggers an independent retrieval. A chatbot makes one
retrieval per user turn — 100ms is invisible. A 20-step agent
reasoning chain makes 20 retrievals — 100ms per step becomes
2,000ms of pure retrieval overhead per cycle, before any LLM
reasoning, tool calling, or output generation.
At 150ms per
retrieval with a reranker, a 20-step chain adds 3,000ms per
cycle. In a pipeline processing 200 sessions per day, this
overhead compounds across every session. The fix: route
queries to in-context memory (sub-1ms) or agent memory
(26–35ms) wherever the information exists there — reserving
RAG for genuinely external knowledge the agent does not hold
in its own memory store.
Q6: When should I use agent memory, RAG, or both?
Use RAG when: the agent needs to answer questions from an
external document corpus that it cannot or should not
memorize. Use agent memory when: the agent needs to maintain
continuity across sessions, build on prior decisions, or
self-correct from its own execution history.
Use both when:
the agent needs external knowledge grounding (RAG) and
persistent identity across sessions (agent memory) — which
is every production agent above 10K interactions against
a 100K+ vector corpus. The correct architecture is not a
choice between the two — it is a composition that assigns
each retrieval problem to the system that handles it
correctly at production scale.
From the Architect’s Desk
The most consistent pattern in AI architecture reviews in 2026 is the RAG-only deployment that begins failing at scale and the engineer who cannot identify the failure because retrieval is still returning results.
At 500K vectors with no reranker, cosine similarity retrieves the most similar passage not the most correct one. The second pattern: the memory system without a validation gate. By the time degradation is noticed, cleanup is a full collection audit measured in engineering days.
The hybrid architecture is not sophisticated. It is four components: In-context, Agent Memory, RAG, and Recursive Summarization. Each has a job. None of them do each other’s job. The routing logic is simple.