Production System Design 2026
LLM architecture in 2026 is not just about understanding how transformers work at an academic level. It is about understanding what each architectural decision means for your production AI agent system — and why the decisions your LLM company made about attention mechanisms, context windows, sampling strategies, and inference infrastructure directly determine whether your agent loop is reliable at 500 concurrent sessions or not.
📚 Technical References
- Transformer Architecture: Vaswani et al. (2017) — “Attention Is All You Need”
- KV Cache Optimization: vLLM Documentation (PagedAttention) + Anthropic Prompt Caching Docs
- Sampling & Temperature: OpenAI & Anthropic API Documentation (2025–2026)
- Embedding & Retrieval: MTEB Benchmark + OpenAI Embeddings Guide
All production recommendations in this guide are based on observed system behavior and validated against current LLM provider documentation.
🔬 Primary Research & System References
- Transformer Architecture: Vaswani et al. (2017), “Attention Is All You Need” — View Paper
- KV Cache Optimization: vLLM Documentation (PagedAttention) — vLLM Docs
- Prompt Caching: Anthropic API Documentation — Anthropic Docs
- Sampling & Temperature: OpenAI API Docs — OpenAI Docs
- Embedding Benchmarks: Massive Text Embedding Benchmark (MTEB) — View Leaderboard
Architecture Briefing 2026
Engineering Key Takeaways: LLM Architecture 2026
Architecture FAQ: AI Agent Production
What is LLM architecture and why does it matter for production AI agent systems?
LLM architecture is the technical blueprint that defines how a large language model processes text input, builds internal representations, and generates token-by-token output. For production AI agent systems in 2026, it matters for three reasons:
The model’s architectural decisions about attention span and layer count determine how reliably it follows instructions when context approaches capacity — which every production agent session does.
The architectural sampler (temperature, top-p, top-k) determines whether your agent produces deterministic structured outputs or creative variations. For tool-use chains, determinism is not optional.
KV cache warmth, inference server configuration, and API gateway design determine whether your agent responds in 350ms or 3,500ms at production concurrency.
Standard Definition: LLM Infrastructure 2026
LLM architecture is the neural network design and deployment infrastructure that allows a large language model to receive text input and produce text output — one token at a time, at production scale.
It has two layers that engineers building AI agent systems in 2026 must understand:
Executive Summary: Production AI Agents
An LLM is not a black box. It is a system with specific architectural properties that determine its behavior under your exact production conditions. Understand those properties before you commit to an architecture. Every failure mode in this post was preventable with 30 minutes of architectural review.
Table of Contents

1. The 6 Core LLM Model Architecture Components
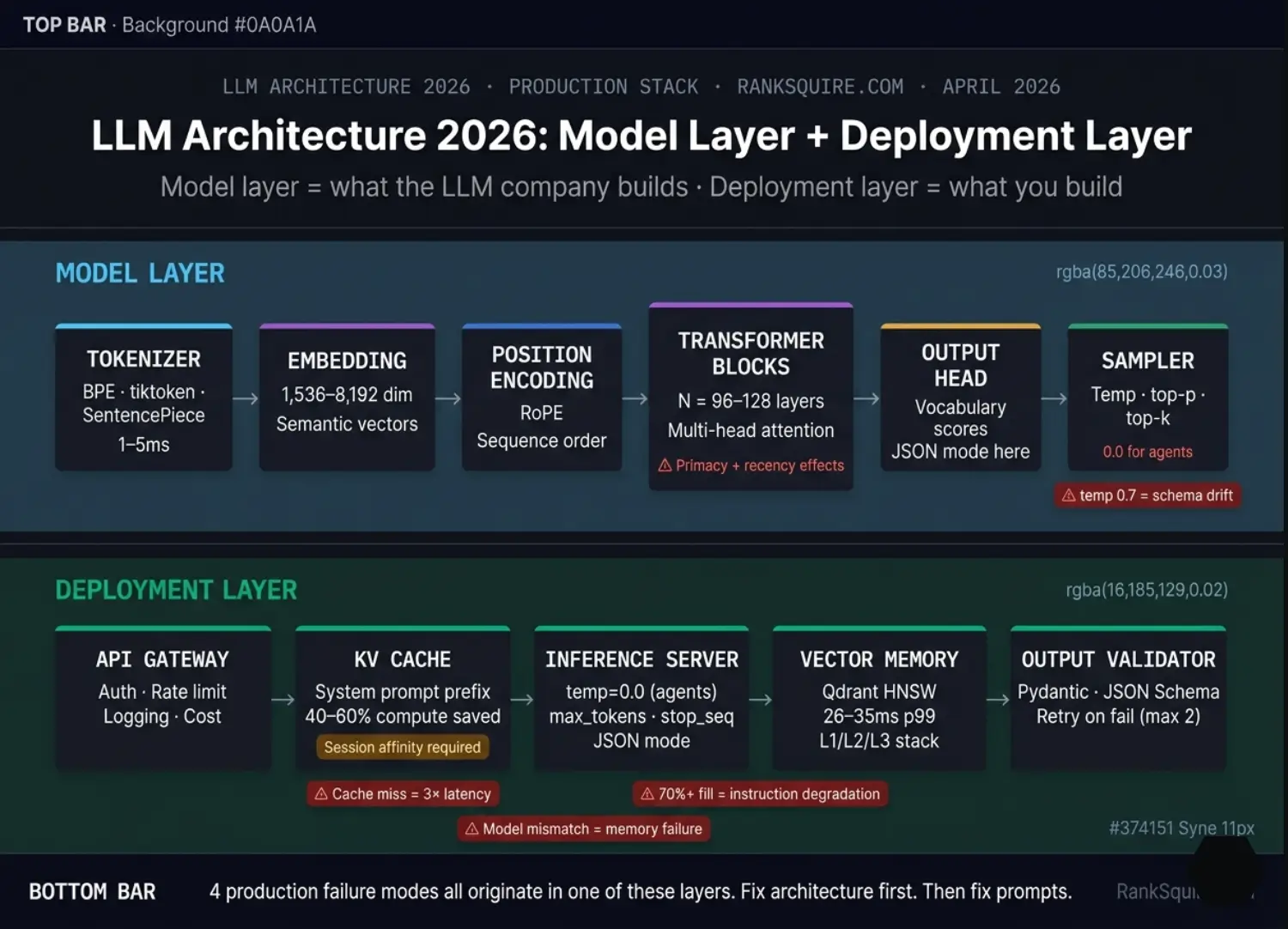
Internal Model Architecture Deep-Dive
Every production frontier model (Claude, GPT-4o, Gemini 1.5 Pro, Llama 3) uses this structure with architectural variations.
The Tokenizer
The Embedding Layer
Positional Encoding
Transformer Blocks — The Attention Mechanism
The Output Head
The Sampler
Temperature 0.7: creative flattens the distribution. Correct for content generation. Catastrophically incorrect for tool-call schemas.
Temperature 1.0: maximum creative variance.
Production agent rule: temperature 0.0–0.2 for all agent steps requiring structured output or tool-call schema generation. Temperature 0.5–0.8 only for content generation steps.
🧩 LLM Model Architecture Flow
2. How Transformers Actually Work: The Engineer’s Version
Performance Mechanics: The 350ms Window
Skip the academic explanation. Here is what a transformer does in the 350 milliseconds between your agent sending a prompt and receiving a response.
Your agent sends a string. The tokenizer splits it into tokens and produces integer IDs. Your 500-word system prompt becomes approximately 625–750 tokens.
Each token ID is converted to a vector by the embedding layer. Your 700 tokens become 700 vectors of 4,096–8,192 dimensions each.
Each token vector is augmented with its positional encoding, preserving sequence order information.
This is where inference time is spent. Each transformer layer applies multi-head self-attention across all tokens simultaneously, then processes through the feed-forward layer. Modern frontier models have 96–128 transformer layers. Each layer’s output feeds the next. The KV cache stores the key-value pairs for all previously processed tokens — so on the next generation step, the model reads from cache rather than reprocessing.
The final layer’s output vector passes through the output head to produce probability scores over the vocabulary. The sampler selects one token. That token is appended to the sequence and the process repeats from Step 4 (the model only needs to process the newly added token — all prior tokens are in the KV cache).
THE LATENCY BUDGET FOR A 500-TOKEN RESPONSE:
| Phase | Duration |
|---|---|
| Steps 1–3: Input Pre-processing | ~20ms (once per request) |
| Step 4 for prompt: Parallel Inference | ~200–400ms (once, full prompt) |
| Steps 4–5 per output token: Sequential Generation | ~5–15ms × 500 tokens = 2,500–7,500ms |
| Total Production Latency | 2,720–7,920ms |
3. Context Windows: What the Headline Number Doesn’t Tell You
📊 Context Attention Zones
System prompt + rules
Memory + RAG (degraded attention)
User input + tool output
Attention is not evenly distributed — placement determines instruction fidelity.
Context Window Quality Analysis
WHAT EVERY ENGINEER USING LLMs IN PRODUCTION NEEDS TO KNOW:
The attention mechanism does not distribute attention equally across the context. Tokens in two positions receive disproportionately high attention:
THE PRODUCTION IMPLICATION FOR AGENT CONTEXT DESIGN:
Do not inject memory in the middle of the context.
- Position 1 (primacy zone): system prompt + persona + rules
- Position 2 (after system prompt): critical task constraints
- Position 3 (memory injection zone): retrieved memories and RAG context — accept that these receive less attention
- Position 4 (recency zone): current user input and tool outputs from the most recent agent step
THE CONTEXT QUALITY DEGRADATION THRESHOLD:
For most frontier models in 2026, instruction-following quality begins to degrade measurably at 60–70% context fill. At 90% fill, the degradation is significant enough to produce visible output quality reduction in structured tool-call scenarios.
Practical rule: design your agent context budget to use no more than 70% of the nominal context window during normal operation.
Claude Sonnet 4.6 at 200K context: use up to 140K tokens in production. GPT-5.4 at 400K: use up to 280K. Gemini 3.1 Pro at 1M: use up to 700K.
📊 Context Attention Zones (Production View)
System Prompt
Memory / RAG (degraded attention)
User Input
4. The Production LLM Deployment Stack
The Deployment Layer: Infrastructure Blueprint 2026
API Gateway
- Rate limit management — queue and retry logic when the LLM provider’s rate limits are hit under burst load
- Retry with exponential backoff — automatic retry on 5xx errors from the inference server
- Request logging — every prompt, every response, every latency measurement — for debugging and cost analysis
- Cost tracking — token count per request × per-token price = cost per agent session
KV Cache (Key-Value Cache)
With warm KV cache: only the new tokens (current user input + latest tool output) are processed. The static context (system prompt, memory injection) is read from cache. Same 500 concurrent sessions: 95% compute reduction for the static portion.
KV cache warmth depends on session affinity: requests from the same session must route to the same inference server replica to hit the warm cache. This requires sticky routing in your load balancer configuration.
Implementation: Anthropic API manages KV caching automatically for repeated system prompt prefixes. For self-hosted models (vLLM, Ollama): enable PagedAttention and configure the KV cache pool size to your peak concurrent session count.
Inference Server
- max_tokens: set to your agent step’s maximum expected output length. Leaving it at default (4,096) when your tool-call schemas are 150 tokens wastes inference compute.
- temperature: 0.0–0.2 for structured output (tool calls, JSON schemas). 0.5–0.7 for generative steps.
- stop sequences: configure explicit stop tokens for your tool-call format to prevent the model from generating beyond the schema end.
- concurrent request limit: configure to your GPU VRAM capacity. Exceeding this causes out-of-memory failures under burst load.
Managed API (Claude, GPT-5.4): the inference server is fully managed. You control temperature, max_tokens, stop sequences, and JSON mode. Rate limits are enforced by the provider.
Self-hosted (vLLM + Llama 4 / Mistral): you control the full inference server configuration including batch size, tensor parallelism across GPUs, and KV cache pool size.
Vector Memory Store
Integration with the LLM deployment stack: at session start, your n8n orchestration layer queries the vector store (Qdrant) for the top-k most semantically similar memory records to the current session context. These records are assembled into the memory injection block and inserted into the context at Position 3 (the memory zone). The inference server receives the context with the memory block already assembled.
For the complete vector memory architecture — see Best Vector Database for AI Agents 2026 at ranksquire.com/2026/01/07/best-vector-database-ai-agents/
Output Validator
Implementation: Pydantic validation for Python-based agents. n8n JSON Schema validator node for workflow agents. Schema validation at this layer, not inside the agent loop’s business logic.
🏗 Production Architecture Flow
5. The 4 Production Failure Modes
⚠️ Architecture Failure Zones (Production View)
- Context Layer: Context degradation at 70% fill
- Sampler Layer: Temperature-induced schema drift
- Infrastructure Layer: KV cache misses
- Memory Layer: Embedding mismatch
Every production failure maps directly to a specific architectural layer — not prompt design.
Post-Mortem: Production Architecture Failure Modes
Every production AI agent failure that cannot be fixed with better prompting originates in one of these four architectural causes.
Context Degradation at High Fill
Mode 1agent output quality drops at session lengths above a threshold. Instructions that work at session start are ignored by session step 8. The model “forgets” rules stated in the system prompt.
context fill approaching 70% threshold. The primacy zone effect diminishes when the static system prompt is a small fraction of a very large context. Critical instructions buried in the middle zone receive insufficient attention.
Temperature-Induced Schema Drift
Mode 2tool-call schemas are correct 95% of the time and wrong 5% — producing agent loop failures that appear random and are extremely difficult to debug because they occur under identical input conditions.
temperature above 0.2 for structured output generation. Even small temperature values introduce sampling variance that occasionally selects slightly different token sequences — producing schemas where a field name has a slightly different capitalization, a required field is missing, or a nested object is not properly closed.
KV Cache Misses Under Burst Load
Mode 3agent latency triples under burst concurrent load without a corresponding increase in input length. P99 latency spikes from 500ms to 2,000ms when concurrent sessions exceed a threshold.
load balancer routing concurrent sessions to different inference server replicas, causing KV cache misses. Each new replica must reprocess the full context from scratch for the first request in a session.
Embedding Model Mismatch
Mode 4retrieved memories are syntactically similar to the query but semantically irrelevant. The agent’s memory retrieval returns records that pass cosine similarity thresholds but contain information that does not actually help with the current session task.
the embedding model used to generate vectors for memory records at ingestion time produces vectors in a different semantic space from the embedding model used to generate the query vector at retrieval time.
🧪 Real-World Case Studies
Case Study 1 — KV Cache Failure at Scale
An internal SaaS automation agent handling ~300 concurrent workflows (n8n + GPT-based tool chains)
Root Cause: Load balancer routing broke session affinity → KV cache misses.
Fix: Sticky sessions enabled → latency reduced by ~60%.
Case Study 2 — Schema Drift from Temperature
Agent tool calls failed intermittently (~5% error rate) despite identical inputs.
Root Cause: Temperature set to 0.7 for structured outputs.
Fix: Reduced to 0.0 + JSON mode → 100% schema consistency.
Case Study 3 — Context Overload Failure
Agent performance degraded after long sessions (~8–10 steps).
Root Cause: Context window exceeded ~75% capacity.
Fix: Recursive summarization + context pruning → stable outputs restored.
6. LLM Architecture for AI Agent Systems: The Complete Diagram
End-to-End Production Pipeline 2026
This is the production architecture that integrates every component covered in this post. Read it left to right — the agent session flows through each layer.
INPUT LAYER
Agent session trigger → n8n orchestration receives task
RETRIEVAL LAYER (parallel queries)
→ L1 Redis: check hot cache for session context (sub-1ms)
→ L2 Qdrant: semantic memory retrieval, top-5 records (26–35ms)
→ L3 Summary: retrieve latest recursive summarization block
CONTEXT ASSEMBLY
Memory injection block assembled from L1 + L2 + L3 results.
Context injection order applied:
Position 1: system prompt (primacy zone)
Position 2: critical constraints
Position 3: memory injection block
Position 4: current user input (recency zone)
Token count verified against 70% context budget limit.
API GATEWAY LAYER
Request authenticated → rate limit checked → routing determined → cost tracking initialized
KV CACHE LAYER
System prompt prefix cache checked → if warm, skip reprocessing → only new tokens sent to inference server
INFERENCE SERVER
temperature=0.0 (structured steps) or 0.5 (generative steps)
max_tokens=configured per step type
stop_sequences=configured for tool-call format
JSON mode=enabled for tool-call steps
OUTPUT VALIDATOR LAYER
Pydantic schema validation → if valid, return to agent loop → if invalid, retry with explicit format correction prompt (max 2 retries) → if failed after retries, route to error handler workflow
OUTPUT ROUTING
Valid tool calls → execute tool → result injected as next user turn. Valid final response → return to session → store in L3 episodic log → Reviewer agent validation → if validated, promote to L2 Qdrant
Recursive summarization job → KV cache warmup job → compliance purge
🧩 End-to-End LLM Production Architecture (2026)
INPUT → Agent Trigger (n8n / API)
RETRIEVAL → Redis (L1) → Qdrant (L2) → Summary (L3)
CONTEXT → System Prompt → Constraints → Memory → User Input
GATEWAY → Auth → Rate Limit → Routing
KV CACHE → Prefix Cache → Session Affinity
INFERENCE → Transformer → Attention → Sampler
VALIDATION → JSON Schema / Pydantic
OUTPUT → Tool Call / Response → Memory Store
Full production flow showing interaction between retrieval, context assembly, inference, and validation layers.
⚠️ Production Rule
In production AI systems, architectural decisions have a larger impact on reliability than prompt design. Optimize architecture first, then refine prompts.
🚫 Never Do This in Production AI Systems
- Using temperature > 0.2 for structured outputs
- Injecting memory before system prompt (breaks primacy effect)
- Running without KV cache at scale
- Mixing embedding models in the same vector store
- Relying on prompts instead of output validation
Result: Intermittent failures, latency spikes, silent accuracy degradation.
7. Conclusion
Closing Thesis: Architectural Integrity
LLM architecture in 2026 is not an academic topic.
It is the engineering foundation that determines whether your AI agent system is reliable at session 500 or broken by session 50.
Tokenizer, embedding layer, attention mechanism, transformer blocks, output head, and sampler — determines the performance envelope you are working within.
API gateway, KV cache, inference server, vector memory store, and output validator — determines how reliably you operate within that envelope.
The four failure modes in this post — context degradation, temperature-induced schema drift, KV cache misses, and embedding model mismatch — account for the majority of production AI agent failures that are incorrectly attributed to prompt quality.
Fix the architecture first. Then fix the prompts.
The Complete LLM Architecture Library
Every guide needed to understand LLM architecture, select the right model, build the production deployment stack, and architect the vector memory layer for AI agent systems.
LLM Architecture 2026: Components, Patterns, Diagrams
Model layer (transformer, attention, sampler) + deployment layer (API gateway, KV cache, vector store, output validator) + the 4 production failure modes and architectural fixes.
LLM Companies 2026: Ranked by Production Readiness
Six LLM companies ranked by the 5 criteria that determine production fit for AI agents — not benchmark scores. Includes the multi-model router that cuts costs by 93%.
⭐ PillarAgentic AI Architecture 2026: The Complete Production Stack
The full agentic architecture that LLM architecture powers: orchestration, memory layers, tool-use loops, and sovereign infrastructure from first principles.
💾 MemoryAgent Memory vs RAG: What Breaks at Scale 2026
The embedding model mismatch failure (Failure Mode 4) explained in depth: where RAG breaks, where persistent vector memory is required, and what retrieval failure looks like.
🗄 Vector StoreBest Vector Database for AI Agents 2026: Full Ranked Guide
The Layer 2 vector memory store (Qdrant) that forms the deployment stack’s persistence layer — ranked against 5 alternatives across 6 production criteria.
LLM in Production 2026: Deployment Patterns and Failure Modes
Complete production deployment guide: load balancing, KV cache configuration, session affinity, prompt prefix caching, and monitoring infrastructure.
8. FAQ: LLM Architecture 2026
What is LLM architecture?
LLM architecture is the technical blueprint of a large language model the neural network design that defines how raw text is processed, how meaning is represented, and how output is generated. The core structure is the transformer architecture, introduced in 2017 and still the foundation of every frontier model in 2026 including Claude 4, GPT-5.4, Gemini 3.1 Pro, and Llama 4.
It consists of a tokenizer, embedding layer, positional encoding, transformer blocks (each containing multi-head self-attention and a feed-forward layer), an output head, and a sampler. For production AI agent systems, the model architecture determines context quality, output consistency, and latency — while the deployment architecture (API gateway, KV cache, inference server, vector memory store, output validator) determines how reliably the model performs under production concurrency.
What is the transformer architecture in LLMs?
The transformer architecture is the neural network design that replaced recurrent neural networks (RNNs) as the
foundation of large language models after its introduction in the 2017 paper “Attention Is All You Need.” It processes entire text sequences simultaneously using a self-attention mechanism allowing every token to compute how much attention it should pay to every other token in the context.
This parallel processing is what makes transformers faster and more capable than sequential RNN architectures. Modern frontier models stack 96–128 transformer layers (each applying self-attention and a feed-forward network), producing outputs that capture increasingly abstract language patterns with each layer. Variations in 2026 include Mixture-of-Experts (MoE) architectures (used in DeepSeek V3, Qwen3-Next) that route each token through specialist expert networks for lower inference compute cost at equivalent quality.
What does the context window mean for AI agent systems?
The context window is the maximum number of tokens an LLM can process in a single inference call simultaneously
holding your system prompt, memory injection block, tool call history, and current user input. For AI agent systems, context window management is critical because: (1) instruction following quality degrades at high fill levels (begin degrading at 60–70% capacity for most models), (2) the attention mechanism distributes attention unevenly (primacy and recency zones receive more attention than the middle), and (3) every additional token in context increases inference compute cost quadratically.
Production rule: use no more than 70% of the nominal context window to preserve a quality buffer and enable recursive summarization to prevent context overflow across long agent sessions.
What is a KV cache and why does it matter for LLM performance?
KV cache (key-value cache) stores the attention key-value matrices for previously processed tokens in an LLM inference session. When your agent sends the same system prompt on every call (as all agents do), a warm KV cache means the model reads the static context from cache rather than reprocessing it in every transformer layer on every call.
Without KV caching, a 10,000-token system prompt at 500 concurrent agent sessions requires reprocessing 5 million tokens per second in inference compute. With warm KV caching, only the new tokens per session (user input and latest tool output) require processing reducing compute by 40–60% at production concurrency. The Anthropic API automatically caches repeated system prompt prefixes. For self-hosted inference (vLLM), enable PagedAttention and configure session affinity in your load balancer.
What temperature should I use for AI agent tool calls?
Temperature 0.0 for all AI agent steps that require structured output tool-call schemas, JSON responses,
database query templates, or any output that is parsed by downstream code. Temperature controls the variance
of the sampling distribution: temperature 0.0 always selects the highest probability token, producing identical
outputs for identical inputs.
Temperature 0.7 introduces meaningful sampling variance correct for creative
generation but destructive for structured output schemas where a single incorrect token (wrong field capitalization,
missing quote, mismatched bracket) causes downstream parsing failure. Use temperature 0.5–0.7 only for explicitly generative steps within the agent loop where creative variance is a feature, not a failure mode.
What is Mixture-of-Experts (MoE) architecture in LLMs?
Mixture-of-Experts (MoE) is an LLM architectural variant that replaces each standard feed-forward layer in a transformer block with multiple specialized “expert” feed-forward networks. Each token is routed to 2–8 experts (selected by a trainable routing network) rather than processed by a single large feed-forward layer.
MoE increases total model capacity (more expert parameters) while reducing active compute per token (only 2–8 experts
activate per token instead of all parameters). Production benefit: lower inference latency and compute cost at equivalent or superior quality. 2026 MoE models include DeepSeek V3/R1, Qwen3-Next, and several Mistral variants. The deployment consideration: MoE models require more total GPU memory (all expert parameters must be loaded) but lower active VRAM utilization per forward pass compared to dense models of equivalent quality.
9. FROM THE ARCHITECT’S DESK
Internal Lab Notes: Common Anti-Patterns
Both of these are 30-second fixes once you understand the underlying architecture. Which is why understanding the architecture is not optional for engineers who want their agent systems to be reliable in production.