Engineering Blueprint 2026
Every other post in this SERP tells you to “pick LangGraph or CrewAI.” This post gives you what none of them publish:
Engineering Blueprint
Engineering Blueprint 2026
AI agent orchestration is the coordination layer in a multi-agent system that manages task decomposition, inter-agent communication, state persistence, and failure recovery — enabling multiple specialized AI agents to collaborate on complex goals that no single agent could complete reliably alone. In 2026, orchestration is the deployment-time middleware that models multi-agent decision-making as a constrained optimization problem: balancing latency, cost, and policy compliance to coordinate specialized agents toward a shared objective.
Engineering Blueprint 2026
Engineering Blueprint 2026
RankSquire.com — Production AI Agent Infrastructure 2026
Engineering Blueprint 2026
The SERP is full of posts that say “orchestration is important” and then list the same six frameworks. None of them give you the production architecture, the cost model, or the failure mode playbook.
2026 Orchestration Law: Your agent produces impressive demos at 80% reliability. Production requires 99%+. The engineering cost of the 19-point gap — circuit breakers, retry logic, context management, observability, and version control — is the orchestration investment. There are no shortcuts.
Table of Contents

1. What Is AI Agent Orchestration? The Production Definition
Engineering Blueprint 2026
AI agent orchestration is not workflow automation with AI branding. It is categorically different in three ways that matter for engineers.
(Zapier, n8n simple flows, BPMN): executes a fixed sequence of steps with predetermined inputs and outputs. When a step fails, the workflow stops. The system does not reason about the failure — it alerts a human and waits.
manages agents that reason, decide, and act dynamically. When a sub-agent fails, the orchestrator can retry with a different approach, delegate to a different agent, escalate to a human with context, or rollback to a known-good state. The system reasons about the failure and takes corrective action.
The distinction is not semantic. It determines your entire architecture: state management strategy, failure recovery design, observability requirements, and cost model all differ fundamentally between fixed workflow automation and dynamic agent orchestration.
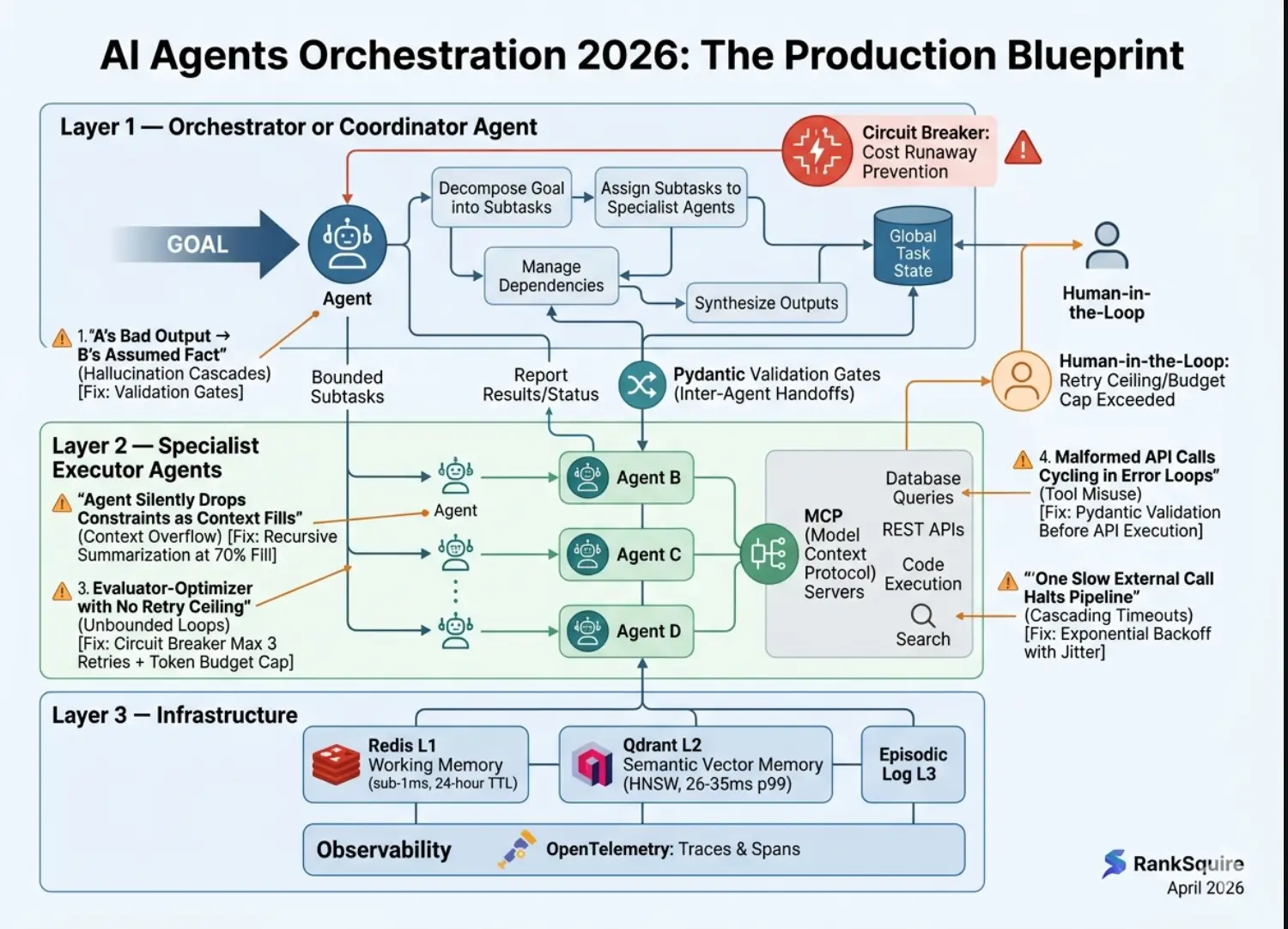
THE THREE LAYERS OF AI AGENT ORCHESTRATION:Receives the goal, decomposes it into subtasks, assigns subtasks to specialist agents, manages dependencies between subtasks, and synthesizes outputs into a coherent result. The orchestrator holds the global task state.
Receive specific, bounded subtasks from the orchestrator. Each specialist agent has access to a defined set of tools (APIs, databases, code interpreters, search, etc.) and operates within its defined scope. Specialist agents report results and status back to the orchestrator — they do not directly coordinate with each other unless the architecture explicitly allows it.
Memory store (Redis L1, Qdrant L2, episodic log L3), tool registry (MCP servers for standardized tool access), observability layer (OTel traces and spans), governance layer (policy checks, cost guardrails, human-in-the-loop escalation routing), and the communication bus between the orchestrator and agents.
For the complete memory architecture that Layer 3 requires — see Agent Memory vs RAG: What Breaks at Scale 2026 at ranksquire.com/2026/agent-memory-vs-rag-what-breaks-at-scale-2026/
2. Do You Actually Need Multi-Agent? The Decision You Must Make First
Engineering Blueprint 2026
Before you evaluate any framework, answer this question honestly:
What this means in practice: If your task is well-defined with predictable subtask boundaries, a single well-configured agent with multiple tools frequently outperforms a multi-agent system while costing less to build, less to operate, and less to debug.
The answer to “buy vs build” is almost always “buy and customize” for production systems — build the critical custom logic on top of a framework foundation, do not re-implement state management and retry logic from scratch.
3. The 5 Core Orchestration Patterns
Engineering Blueprint
Five patterns cover the vast majority of production AI agent orchestration needs. Match your task to the correct pattern before choosing a framework — the framework decision follows naturally.
When to use:
- Tasks with strict data dependencies (each step requires the previous step’s output as input)
- Compliance-sensitive workflows requiring audit trail per step
- Content processing pipelines (research → draft → review → publish)
When to use:
- Tasks where subtasks are genuinely independent
- Multi-source research (each agent queries a different source)
- When latency matters more than cost (parallelism reduces wall-clock time)
Fan-in synthesis strategies: Voting, Weighted merging, LLM synthesis, Structured aggregation.
When to use:
- Complex enterprise workflows with many specialist domains
- When the orchestration logic itself requires reasoning
- When task scope is unpredictable and requires dynamic spawning
When to use:
- Customer support systems (route by intent to specialist agent)
- When simple tasks are the majority but some require deep specialist handling
- Cost-sensitive environments requiring minimal overhead
When to use:
- Code generation (executor generates, evaluator runs tests)
- Document generation requiring specific quality standards
- Any task where quality cannot be guaranteed in a single pass
4. The Orchestration Overhead Matrix
Engineering Blueprint
This table does not exist anywhere else in the current SERP. It is derived from research data, production deployment reports, and the Princeton NLP multi-agent benchmark findings. Use this matrix to justify your pattern choice before building.
| Pattern | Accuracy Gain | Cost Mult | Latency vs Single | When Worth It |
|---|---|---|---|---|
| Sequential Pipeline | +2–4% | 1.5–2× | 2–4× (3–8s) | Data dependencies, Compliance audit |
| Parallel Fan-Out | +4–8% | 2–3× | 0.8–1.2× (1–2s) | Independent tasks, Speed > cost |
| Hierarchical Supervisor | +6–12% | 3–5× | 5–15× (15–45s) | Complex reasoning, Unknown scope |
| Dynamic Router | +1–3% | 1.1–1.5× | 1.2–2× (1–3s) | Cost efficiency, Mixed complexity |
| Evaluator-Optimizer | +8–15% | 4–8× | Variable (20–90s) | Quality-critical, Automated validation |
• Sequential 3-agent: 3–8 seconds, $0.01–0.025/task
• Hierarchical 5-agent: 15–45 seconds, $0.05–0.30/task
• Evaluator loop (3 iterations): 30–90 seconds, $0.10–0.60/task
5. Framework Selection: 2026 Production Status
Engineering Blueprint
This table does not exist anywhere else in the current SERP. It is derived from research data, production deployment reports, and the Princeton NLP multi-agent benchmark findings. Use this matrix to justify your pattern choice before building.
| Framework | Status | Best For | Latency Overhead | Obs. Depth | MCP | A2A |
|---|---|---|---|---|---|---|
| LangGraph | ✅ Active Production | Complex state DAG workflows, Regulated use | Medium (50–100ms per hop) | Deep (LangSmith) | ✅ Full | ⚠ Partial |
| CrewAI | ✅ Active Production | Role-based crews, rapid deployment | Low (30–60ms per hop) | Medium (built-in logs) | ✅ Full | ✅ (2026 Flows) |
| OpenAI Agents SDK | ✅ Active Production | OpenAI-native thin abstraction simple agents | Very low (20–40ms per hop) | Light (OTel needed) | ✅ (external) | ❌ No |
| Google ADK | ✅ Active Production | Gemini + GCP hierarchical | Low (30–60ms per hop) | Medium (Cloud Trace) | ✅ (native) | ✅ (native) |
| Microsoft Agent Framework | ✅ Active Production | .NET enterprise Azure-native regulated | Medium (60–120ms per hop) | Deep (Azure Monitor) | ✅ (native) | ✅ (native) |
| AutoGen (AG2) | ⚠ Caution Legacy ONLY | Slowing conversational | High (80–150ms per hop) | Medium (custom needed) | ⚠ (contrib) | ⚠ (contrib) |
If you are evaluating AutoGen for a new project in 2026: do not. Use Microsoft Agent Framework instead.
If you are already in production on AutoGen: plan your migration path to Microsoft Agent Framework now. The migration does not require rewriting agent logic — the Agent Framework is designed to accept AutoGen-style agent definitions — but do not build new production systems on AutoGen.
The observability depth via LangSmith is the strongest of any open-source framework — traces, spans, token consumption, tool call logging, and latency histograms are all native.
- • Complex stateful workflows, regulated environments, or maximum observability → LangGraph
- • Role-based crews, rapid deployment, event-driven coordination → CrewAI
- • Gemini-native systems or A2A-first architecture → Google ADK
- • .NET enterprise or Azure-native regulated environments → Microsoft Agent Framework
- • OpenAI-native, simple agent patterns, minimal abstraction overhead → OpenAI Agents SDK
- • No new production systems → AutoGen (migrate to Agent Framework)
6. The Protocol Stack: MCP + A2A
Engineering Blueprint
In 2026, two protocols define how agents connect to the world and to each other. Understanding the distinction is not optional for production architecture.
Originated by Anthropic in late 2024, now governed by the Linux Foundation’s Agentic AI Foundation (AAIF) alongside A2A.
Production use: an agent in your orchestration system needs to query a database, call a REST API, execute code, or read from a file system. These capabilities are exposed as MCP servers. The agent connects to the MCP server, discovers available tools, and calls them through the standard interface.
When to use MCP: for all agent-to-tool connections in 2026. Custom API connectors are the legacy pattern. MCP servers provide standardized discovery, authentication, and error handling that custom connectors must implement manually.
Originated by Google, now governed by AAIF alongside MCP.
Production use: in a hierarchical orchestration system, the supervisor agent delegates to specialist agents. If those specialist agents are built on different frameworks (common in large organizations), A2A provides the standard communication layer.
When to use A2A: when your orchestration system spans multiple frameworks, providers, or teams. For single-framework deployments, native framework communication is simpler. For cross-framework or cross-organization agent calls, A2A is the correct abstraction.
The Linux Foundation’s Agentic AI Foundation launched December 2025 with six co-founders: OpenAI, Anthropic, Google, Microsoft, AWS, and Block. Both MCP and A2A are now under AAIF governance.
7. The 5 Production Failure Modes
Engineering Blueprint
Every production AI agent orchestration system fails in one of five ways. These are not edge cases. They are the predictable failure modes of every orchestration architecture that has not been explicitly engineered against them.
Why it is worse in multi-agent: single agents can be prompted to express uncertainty. Multi-agent systems convert Agent A’s tentative output into confirmed input for Agent B, systematically eliminating uncertainty signals.
The fix: implement a validation gate at every inter-agent handoff. Validate structured output against a Pydantic schema.
Warning signal: the agent begins ignoring constraints it was following 20 messages ago. Not an error — no exception is thrown.
The fix: implement recursive summarization at the orchestration layer when agent context exceeds 70% of the model’s window.
For the architecture behind context management — see LLM Architecture 2026 at ranksquire.com/2026/llm-architecture-2026/
The fix: Mandatory guardrails. Set a retry ceiling (max 3) and a total token budget cap per task.
The fix: implement Pydantic validation on every tool call schema at the MCP server layer. Validate inputs before the API call is made.
The fix: implement non-linear timeout budgets and use exponential backoff with jitter.
8. Cost Modeling: What AI Agent Orchestration Actually Costs
Engineering Blueprint
This is the data no competitor publishes. These figures are drawn from production cost reports and architecture reviews.
BUILD COST BY SYSTEM COMPLEXITY:→ Build cost: $10,000–$50,000
→ Timeline: 4–8 weeks with 2 engineers
→ Correct for: well-defined, stable use cases with clear scope
→ Build cost: $50,000–$400,000
→ Timeline: 3–6 months with 3–5 engineers
→ Correct for: enterprise workflow automation, multi-department systems
→ Build cost: $400,000–$1,500,000+
→ Timeline: 6–18 months with 5–15 engineers
→ Correct for: mission-critical, regulated, multi-tenant platforms
• Simple task (avg 2,000 tokens): 10K × 2K × $0.003/K = $60/day = $1,800/month
• Medium task (avg 10,000 tokens): 10K × 10K × $0.003/K = $300/day = $9,000/month
• Complex task (avg 30,000 tokens): 10K × 30K × $0.003/K = $900/day = $27,000/month
Infrastructure (DigitalOcean sovereign stack):
• Orchestration server (n8n): $96/month
• Vector memory (Qdrant self-hosted): $96/month
• Redis (on same Droplet): $0 additional
• LangSmith observability (free to $100/month): $0–100/month
Medium tasks: $9,000 (LLM) + $192 (infra) = ~$9,200/month
Complex tasks: $27,000 (LLM) + $192 (infra) = ~$27,200/month
Reduce LLM cost by 60–80% with three optimizations:
For the multi-model routing setup — see Best AI Automation Tool 2026 at ranksquire.com/2026/best-ai-automation-tool-2026/
Engineering Blueprint
Affiliate disclosure: RankSquire.com may earn a commission. All tools production-verified.
9. Observability — The Non-Negotiable Production Layer
Engineering Blueprint
You cannot debug what you cannot trace. In multi-agent systems, an opaque orchestration layer is not just an engineering inconvenience — it is a production liability that makes every failure investigation a multi-hour forensic exercise.
THE MINIMUM VIABLE OBSERVABILITY STACK:OpenTelemetry (OTel) is the 2026 standard for agent observability. Every production orchestration system must instrument:
- Traces: every agent call, its parent task, and the full execution path from orchestrator through to tool call and back.
- Spans: the timing of each step within an agent call — input processing, LLM inference, tool execution, output validation.
- Token usage: input tokens, output tokens, cached tokens, and total cost per trace. Without this, you cannot allocate costs to specific workflows or identify cost-runaway tasks.
- Tool calls: every tool invoked, its input parameters, its output, and its latency. This is how you find tool misuse failures.
- Error events: every retry, every validation failure, every human-in-the-loop escalation, with full context preserved.
Human oversight is not a fallback. It is a designed component. The escalation matrix defines exactly which conditions route to human review — and what information the human receives.
- Evaluator-Optimizer retry ceiling reached
- Token budget cap hit before task completion
- Agent output confidence below threshold (< 0.7)
- Tool call failure after 3 retries
- Task involves regulated data types (PHI, PII, financial) and automated validation fails
- The original task description
- The best attempt produced so far
- The specific reason for escalation
- The full trace for forensic review
For the complete LLM deployment stack that this observability layer sits above — see LLM Architecture 2026 at
ranksquire.com/2026/llm-architecture-2026/
10. Conclusion
Engineering Blueprint
AI agent orchestration in 2026 is the engineering discipline that determines whether your agentic AI project is in the 11% that reach production or the 89% that do not.
The most important insight from every research source synthesized for this post: orchestration is not about which framework you choose. It is about whether you design the five failure modes out of your architecture before you write the first agent call.
The framework decision follows from the pattern decision. The pattern decision follows from the task analysis. And the task analysis starts with one honest question: does this task actually require multiple agents, or am I adding complexity because multi-agent sounds more impressive?
Use the Orchestration Overhead Matrix in Section 4. Run the numbers for your specific task type. If the accuracy gain at your task’s required reliability level justifies the cost and latency multiplier of multi-agent — build it. If it does not — use a well-configured single agent with multiple tools and spend the saved engineering time on observability instead.
Engineering Blueprint
The Complete Agentic AI Architecture Library
Every guide you need to architect, build, and operate production AI agent systems — from orchestration patterns to memory, LLM selection, and vector infrastructure.
AI Agents Orchestration 2026: The Production Blueprint
5 orchestration patterns · Overhead Matrix · Framework selection · MCP + A2A protocol stack · 5 failure modes · Full cost model.
Agentic AI Architecture 2026: The Complete Production Stack
The full sovereign agentic AI architecture: orchestration layers, L1/L2/L3 memory, tool-use loops, and deployment from first principles.
Read → 🧠 LLM SelectionLLM Companies 2026: Ranked by Production Readiness
The LLMs your orchestration system calls — Claude, GPT-5.4, Gemini, Llama 4 ranked for production agent workloads.
Read → 💾 MemoryAgent Memory vs RAG: What Breaks at Scale 2026
The Layer 3 infrastructure: where RAG breaks, where persistent vector memory is required, and the failure cliffs.
Read → 🔧 Orchestration ToolsBest AI Automation Tool 2026: Ranked by Use Case
n8n vs LangGraph vs Zapier vs Make — ranked by AI agent depth, cost at scale, and sovereignty.
Read →LangGraph Production Guide 2026: Stateful Agent Architecture
Deep dive into LangGraph v0.3.0 — DAG workflows, durable state, and time-travel debugging.
11. FAQ: AI Agents Orchestration 2026
What is AI agent orchestration?
AI agent orchestration is the coordination layer in a multi-agent system that manages task decomposition, inter-agent communication, state persistence, and failure recovery enabling multiple specialized AI agents to collaborate on complex goals that no single agent could complete reliably alone. It is categorically different from workflow automation: orchestration manages dynamic reasoning and failure recovery, not fixed step sequences.
In 2026, orchestration is the difference between an AI agent demo that works 80% of the time and a production system that delivers 99%+ task completion reliability at enterprise scale.
What is the best framework for multi-agent orchestration in 2026?
For complex stateful workflows with maximum observability: LangGraph (v0.3.0 with native DAG workflows, durable checkpointing, and LangSmith trace integration). For role-based crews and rapid deployment with event-driven coordination: CrewAI with Flows (2026 addition native MCP and A2A support).
For Gemini-native systems and A2A-first architecture: Google ADK. For .NET enterprise and Azure-regulated environments: Microsoft Agent Framework. Do not start new production projects on AutoGen Microsoft has shifted
focus to the broader Agent Framework and AutoGen’s major feature development has slowed significantly.
What are MCP and A2A and how do they work together?
MCP (Model Context Protocol) is the standard protocol for agent-to-tool communication it defines how AI agents connect to external APIs, databases, and services. A2A (Agent-to-Agent Protocol) is the standard
for agent-to-agent communication it defines how AI agents across different frameworks communicate with each other.
Both were originally developed by Anthropic (MCP) and Google (A2A) and are now governed by the Linux Foundation’s Agentic AI Foundation (AAIF), launched December 2025. In production: use MCP for all tool connections (database queries, API calls, code execution) and use A2A when your orchestration spans multiple agent frameworks or organizational boundaries.
Why do 40% of agentic AI projects fail?
Gartner and Camunda data both point to the same root causes: orchestration failures, not model failures. The five most common production failure modes are hallucination cascades (A’s bad output becomes B’s assumed fact), context overflow (agent silently drops earlier constraints as context fills), unbounded loops (Evaluator- Optimizer retries with no ceiling → cost runaway), tool misuse (malformed API calls that cycle in error loops), and cascading timeouts (one slow external call halts the entire pipeline).
All five are architectural problems with specific architectural fixes — see Section 7.
How much does AI agent orchestration cost to build and operate?
Build cost ranges from $10K–$50K for simple 3–5 agent systems (4–8 weeks, 2 engineers) to $400K–$1.5M+ for full autonomous platforms with memory, compliance, and human-in-the-loop at scale. Monthly operational cost at 10,000 tasks/day: approximately $2,000/month for simple tasks (2K average tokens), $9,200/month for medium tasks (10K
average tokens), and $27,200/month for complex tasks (30K average tokens) using mixed frontier and cheap model routing.
Three cost optimizations reduce LLM spend by 60–80%: multi-model routing (70% cheap models,
10% frontier), prompt prefix caching (90% discount on repeated system prompt tokens), and LangGraph’s native state caching (40–50% fewer redundant LLM calls).
Is multi-agent orchestration always better than single agent?
No. Princeton NLP research found that a single agent matched or outperformed multi-agent systems on 64% of benchmarked tasks when given the same tools and context. Multi-agent adds approximately 2.1
percentage points of accuracy at roughly double the cost and 10–30× the latency.
Multi-agent is justified when tasks require true parallelism, genuinely different specialist capabilities across subtasks, context windows too long for single-pass completion, or regulatory requirements
for separate agent audit trails.
For most well-defined tasks with predictable scope, a single agent with multiple tools through MCP
is faster, cheaper, and easier to debug in production.
Engineering Blueprint
The two questions I ask every team evaluating AI agent orchestration before they write a line of code:
Most tasks do not require multiple agents. The most expensive mistake in production agentic AI is building a hierarchical supervisor architecture for a task that a single agent with five MCP-connected tools would handle more reliably at one-fifth the cost.
If the answer is “it passes it to Agent C” — that is the hallucination cascade failure mode already embedded in the architecture. The validation gate is the answer. It must be in the design before the first agent call.
The 40% project cancellation rate is not random. It clusters around teams that made these two decisions wrong: built more complexity than the task required, and did not design failure recovery before writing orchestration code.
Design for failure first. Then build for success.